 Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy
Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy





Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy


-

-

- AULE GRUPPI
-
 Le Tue Aule
Le Tue Aule
-
 I Tuoi Gruppi
I Tuoi Gruppi
-
 Le Tue Selezioni
Le Tue Selezioni
-
Tutte le categorie
Full Stack Developer
 Antonella Visciano |
Antonella Visciano |
 Skill Factory - 07/05/2026 11:23:00 | in Formazione e lavoro
Skill Factory - 07/05/2026 11:23:00 | in Formazione e lavoro
PASSAPAROLA!
Per rispondere all'alto numero di richieste ricevute, abbiamo aperto le selezioni per il nuovo corso "Java Full Stack Developer". Il corso gratuito, finanziato Forma.Temp, è rivolto a giovani diplomati o laureati in cerca di occupazione e verrà erogato in presenza presso la nostra Academy di Napoli.
Affrettati, invia il tuo CV a selezione@skillfactory.it oppure contattaci attraverso il nostro sito www.skillfactory.it, cliccando sulla scheda del corso.


1° MAGGIO: FESTA DEL LAVORO E DELLA FORMAZIONE
![]() Gino Visciano |
Skill Factory - 01/05/2026 12:42:00 | in Formazione e lavoro
Gino Visciano |
Skill Factory - 01/05/2026 12:42:00 | in Formazione e lavoro
Per noi della Skill Factory, il 1° maggio non è solo la festa del LAVORO, ma è anche la festa della FORMAZIONE.

Il lavoro è fondamentale perché crea stabilità e sicurezza personale e sociale; deve essere, e rimanere, un diritto di tutti. Quando faccio formazione, cerco sempre di trasmettere agli studenti una consapevolezza: il lavoro non si "cerca" semplicemente, ma si crea e si costruisce attraverso la conoscenza, l'impegno e l'esperienza.
In questo senso, la formazione ha un ruolo strategico perché trasforma la teoria in competenza e la competenza in opportunità reali di occupazione.
In Skill Factory abbiamo una Mission chiara: non facciamo formazione "per progetto", ma la intendiamo come lo strumento concreto per creare posti di lavoro.
La nostra Mission e la nostra Vision convergono in un unico punto: creare occupabilità reale.
Il lavoro non è solo un dovere, è il fondamento di una società giusta e stabile. Ma per essere tale, deve essere qualificato. Ecco perché crediamo fermamente nel LifeLong Learning: la formazione non è un evento isolato, ma un vero e proprio progetto di vita. È l'unico strumento che permette ai lavoratori di restare competitivi e alle aziende di crescere in un mercato in continua evoluzione e trasformazione.
Per questo motivo, il nostro impegno futuro rimarrà quello di trasmettere competenze tecniche e umane di alto profilo, per indirizzare gli studenti che formiamo verso le reali necessità del mercato del lavoro e garantire la Qualità attraverso standard rigorosi (come quelli EQAVET).
In questa giornata speciale, voglio rivolgere un riconoscimento profondo a tutti gli attori del mondo dell'IFP (Istruzione e Formazione Professionale). A chi, come noi, ogni giorno si spende per formare, orientare e accompagnare le persone verso un impiego dignitoso.
Grazie al vostro impegno, contribuiamo insieme a rendere il lavoro non solo possibile, ma solido e gratificante.
Buon Primo Maggio a chi lavora, a chi cerca lavoro e a chi, con passione, contribuisce a costruirlo.
Operatore Amministrativo Contabile
Antonella Visciano |
Skill Factory - 09/04/2026 12:37:01 | in Formazione e lavoro
Nel contesto attuale, la figura dell’Operatore Amministrativo Contabile rappresenta una competenza fondamentale sia per l’ingresso nel mondo del lavoro sia per chi desidera prepararsi ai concorsi pubblici, in particolare per il personale ATA.

All'interno della nostra Academy, questo percorso è tra i più scelti da giovani in cerca di occupazione e da chi vuole acquisire competenze utili per affrontare selezioni in ambito amministrativo scolastico e aziendale.
Il valore del corso risiede nella sua natura pratica e completa, capace di fornire basi solide in ambito contabile, organizzativo e digitale, competenze sempre più richieste sia nel settore privato che nella pubblica amministrazione.
A fine corso avrai acquisito le seguenti competenze:
• Sistema azienda: organizzazione aziendale e processi amministrativi;
• Contabilità: gestione delle scritture contabili e principali adempimenti;
• Segreteria efficiente: comunicazione professionale, gestione documentale e pubbliche relazioni;
• Competenze digitali: informatica generale e utilizzo degli strumenti di Office Automation.
La forza del nostro programma risiede nella sua concretezza. Al termine del percorso, i partecipanti potranno ricoprire diversi ruoli in ambito amministrativo, tra cui:
• Operatore Amministrativo;
• Addetto alla contabilità di base;
• Impiegato di segreteria organizzativa;
• Assistente amministrativo.
Grazie a un approccio pratico e orientato al mondo del lavoro, i partecipanti saranno pronti a inserirsi in contesti aziendali, portando con sé competenze operative e una solida capacità organizzativa.
Il prossimo corso per "Operatore Amministrativo Contabile", presso la nostra Academy, parte il 29 aprile 2026.
Il corso è rivolto a giovani disoccupati/inoccupati che vogliono acquisire competenze nel settore amministrativo e contabile e ha le seguenti caratteristiche:
• Durata: 120 ore di formazione
• Modalità di erogazione: 100% online (comodamente da casa)
• Costo: GRATUITO (finanziato da Forma.Temp)
• Orari: dal lunedì al venerdì, dalle 9:30 alle 17:30
👉 Tutti gli allievi che completeranno il percorso formativo riceveranno:
🔹 Attestato di "Operatore Amministrativo Contabile" (Forma.Temp)
🔹 Attestato di sicurezza sul lavoro (valido un anno)
• Come partecipare:
Invia il tuo CV e una manifestazione di interesse a: selezione@skillfactory.it oppure compila il modulo cliccando qui.
I posti sono limitati!
Per maggiori informazioni consulta il sito: www.skillfactory.it
Tecnico Programmatore: Il Profilo più richiesto dai giovani che frequentano la nostra Academy
Antonella Visciano |
Skill Factory - 17/03/2026 15:14:41 | in Formazione e lavoro
Nel mercato del lavoro odierno, la figura del Tecnico Programmatore si è consolidata come il pilastro fondamentale della trasformazione digitale.

All'interno della nostra Academy, questo profilo professionale è sicuramente tra quelli più gettonati dai giovani in cerca di competenze per entrare nel mondo del lavoro, e maggiormente ricercato dalle aziende che assumono junior.
Il motivo di questo successo risiede nella natura ibrida e completa del percorso formativo, capace di trasformare la passione per il codice in una competenza tecnica solida e immediatamente spendibile.
A fine corso avrai acquisito le seguenti competenze:
• Linux/MSDOS,
• Reti, Pila ISO/OSI,
• Logica di programmazione con Python,
• Algoritmi notevoli con Python,
• Linguaggio SQL,
• Object Oriented con UML,
• Linguaggio Java,
• GIT/MAVEN,
• HTML/CSS,
• JavaScript,
• Spring,
• Microservizi,
• Docker,
• Il ciclo di sviluppo DevOps,
• Processo CI/CD.
La forza del nostro programma risiede nella trasversalità. Al termine del percorso, i partecipanti possono ricoprire i seguenti ruoli strategici nelle diverse aree dell'Information Technology:
• Programmatore Back-end, con conoscenze di micro-servizi;
• Programmatore Front-end, capace di sviluppare applicazioni Web;
• Software Tester funzionale (ISTQB);
• Database Administrator;
• Analista Funzionale.
Grazie a un approccio pratico e orientato al mondo del lavoro, i giovani che partecipano ai nostri percorsi di formazione sono pronti a inserirsi in team di sviluppo, portando con sé non solo competenze di coding, ma anche una mentalità orientata all'Agilità e alla Qualità.
Il prossimo corso per "Tecnico Programamtore", presso la nostra Academy, parte il 22 aprile 2026.
Il corso è rivolto a giovani in cerca di occupazione che vogliono entrare nel mondo dell’informatica e dello sviluppo software e ha le seguenti caratteristiche:
• Durata: 240 ore di formazione
• Modalità di erogazione: In presenza
• Costo: GRATUITO (finanziato da Forma.Temp)
• Orari: dal lunedì al venerdì, dalle 9:30 alle 17:30
• Come partecipare:
Invia il tuo CV e una manifestazione di interesse a: selezione@skillfactory.it oppure compila il modulo cliccando qui.
I posti sono limitati!
Per maggiori informazioni consulta il sito: www.skillfactory.it
6.L'Assicurazione della Qualità nell'IFP
![]() Gino Visciano |
Skill Factory - 24/01/2026 00:01:12 | in Home
Gino Visciano |
Skill Factory - 24/01/2026 00:01:12 | in Home
Prima di approfondire il tema dell'Assicurazione della Qualità nell'Istruzione e Formazione Professionale (IFP), è fondamentale chiarire la distinzione tra tre concetti spesso sovrapposti: Educazione, Istruzione e Formazione.

Educazione (Saper essere)
L'educazione riguarda la sfera dei valori, del comportamento e della personalità. È un processo che dura tutta la vita e serve a formare il cittadino e l'individuo. L'obiettivo dell'educazione è trasmettere i principi etici, civici e sociali che costituiscono la base dell'identità delle persone.
Istruzione (Sapere)
L'istruzione riguarda l'acquisizione di conoscenze teoriche e concetti astratti. È il tipico percorso scolastico o accademico tradizionale che fornisce le basi culturali necessarie. L'obiettivo dell'istruzione è fornire agli studenti un bagaglio di informazioni e nozioni (il "cosa").
Formazione (Saper fare)
La formazione è il cuore pulsante dell'IFP. È il processo mirato ad acquisire competenze pratiche e professionalizzanti per svolgere un compito specifico o un mestiere. In sintesi, è la capacità di trasformare la conoscenza in azione (il "come"). L'obiettivo della formazione è fornire competenze concrete e spendibili.
L’Assicurazione della Qualità (AQ) nell'IFP
Assicurare la qualità nell'Istruzione e Formazione Professionale significa garantire che ogni attività formativa sia pertinente, efficace e coerente con gli obiettivi previsti. Se l'Assicurazione della Qualità rappresenta il processo, gli obiettivi ne costituiscono la meta.
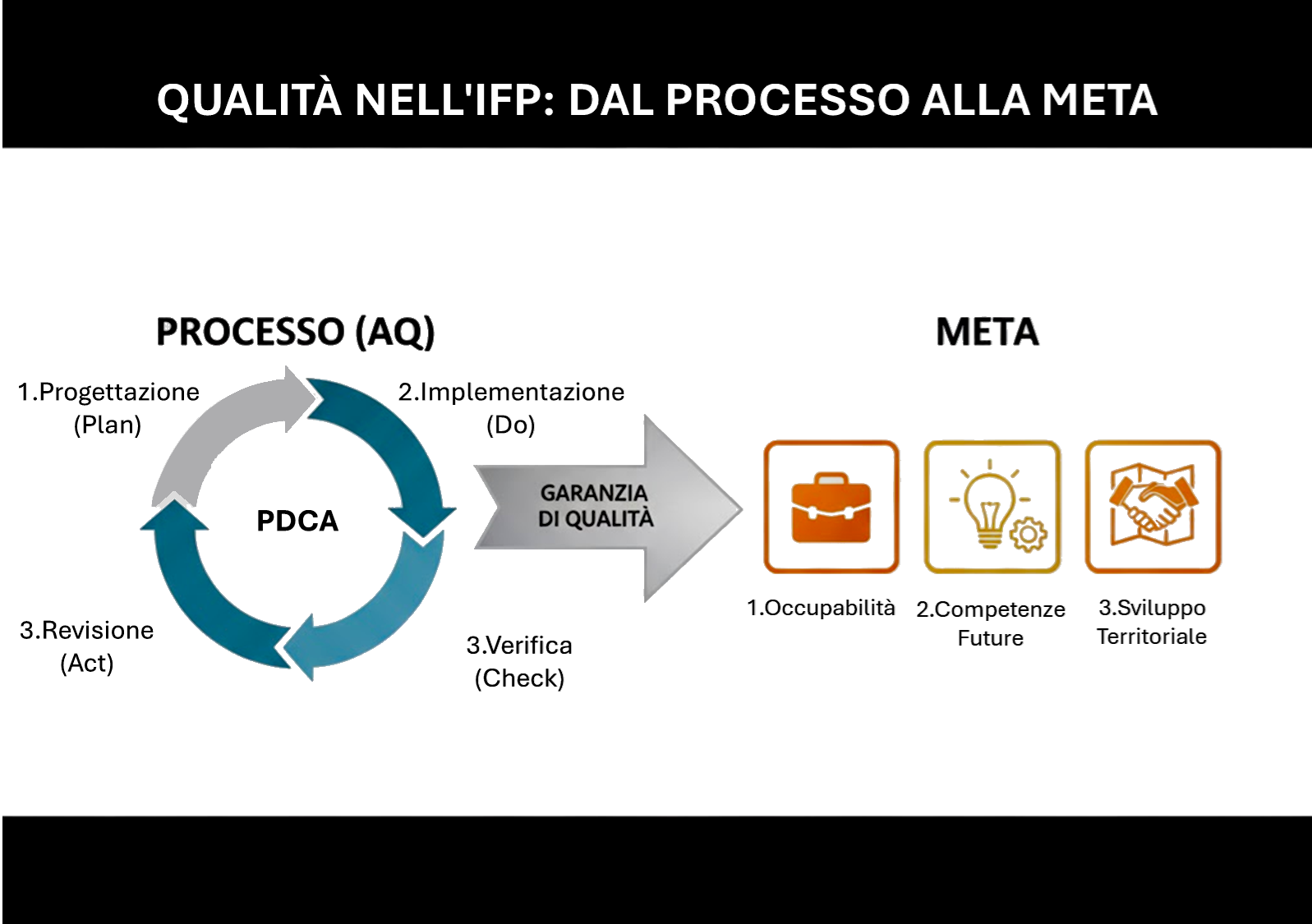
In questo contesto, gli obiettivi non riguardano solo il "sapere", ma soprattutto il "saper fare" e il "saper essere". Gli obiettivi principali dell'IFP si possono riassumere in tre aree:
1.Obiettivi di Occupabilità: Riduzione del mismatch tra domanda e offerta, inserimento lavorativo rapido e certificazione delle competenze per rendere il profilo dello studente competitivo sul mercato.
2.Obiettivi Educativi e Metodologici: Apprendimento esperienziale ("imparare facendo"), sviluppo di soft skills e promozione dell'apprendimento permanente (lifelong learning), fondamentale in settori ad alta evoluzione come l'Intelligenza Artificiale.
3.Obiettivi Strategici per il Territorio: Supporto all'innovazione aziendale, inclusione sociale e capacità di adattare i programmi alle evoluzioni tecnologiche e normative.
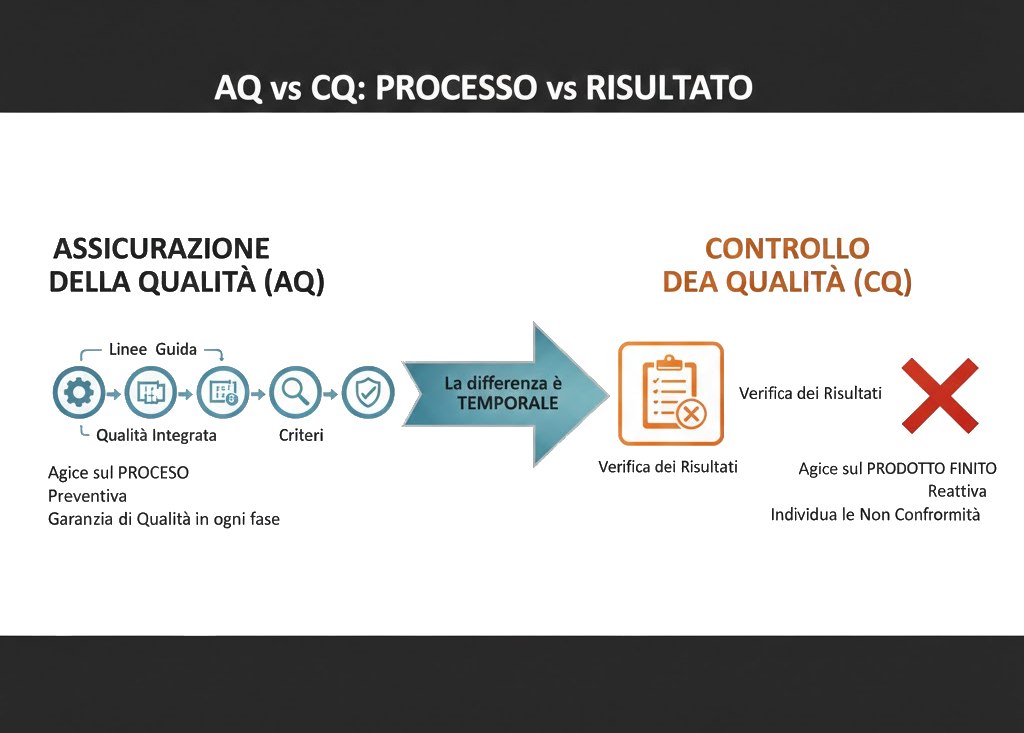
Differenza tra Assicurazione della Qualità (AQ) e Controllo della Qualità (CQ)
È essenziale distinguere tra Assicurazione della Qualità (AQ) e Controllo della Qualità (CQ), queste due funzioni spesso confuse:
L'Assicurazione della Qualità (AQ) agisce sul processo. Stabilisce preventivamente le linee guida, le metodologie, i criteri e le regole da rispettare per garantire che la qualità sia integrata in ogni fase.
Il Controllo della Qualità (CQ) interviene invece a valle per verificare i risultati prodotti. Il suo scopo è individuare eventuali non conformità una volta che il processo è terminato.
L'Unione Europea: Le Raccomandazioni
L'Unione Europea, attraverso le Raccomandazioni, indica agli Stati membri gli obiettivi comuni da seguire per assicurare la qualità e modernizzare i sistemi formativi. Poiché l'istruzione è una competenza dei singoli Stati, l'UE non impone leggi uniche, ma utilizza le Raccomandazioni per creare un linguaggio comune e definire i risultati attesi.

Le Raccomandazioni e gli strumenti più rilevanti sono:
1.EQF (European Qualifications Framework): Istituito nel 2008 e aggiornato nel 2017, è la griglia che definisce gli 8 livelli di competenza. Permette di confrontare i titoli di studio tra nazioni diverse, spostando il focus dall'input (cosa si è studiato) all'output (risultati di apprendimento).
2.EQAVET (European Quality Assurance in Vocational Education and Training): Adottato nel 2009 e rafforzato nel 2020, è il modello specifico per l'assicurazione della qualità nell'IFP. Introduce un ciclo di gestione (PDCA) per garantire il monitoraggio e il miglioramento costante dei corsi.
3.Europass: Nato nel 2004 e rinnovato nel 2018, è lo standard per la trasparenza delle competenze. Trasformatosi in piattaforma digitale, permette di rendere le qualifiche comprensibili ai datori di lavoro di tutta Europa.
Storicamente, questi strumenti sono il frutto di un'evoluzione ventennale volta a creare lo Spazio Europeo dell’Istruzione e della Formazione, garantendo che ogni percorso formativo gli obiettivi attesi dagli Stakeholder.
Approfondimenti:
5.L'Etica della formazione come responsabilità professionale.
4 Buona Formazione: "Come assicurare la qualità della formazione".
3.La qualità della formazione inizia dal confronto.
2.La filiera della Formazione Professionale in Europa e in Italia.
1.Sei uno studente oppure un lavoratore? Scopri qual è il tuo livello di EQF.
Vuoi diventare un "Esperto di Qualità" nell'IFP e migliorare la qualità della Formazione Professionale svolgendo il ruolo di "Pari"?
Il "Pari", è un esperto di "Metodologia Peer Review di EQAVET", collabora con il Natrional Reference Point EQAVET italiano, presso INAPP, per valutare, attraverso visite in loco, gli Istituti/Centri di Formazione della filiera IFP.
Skill Factory in collaborazione con INAPP (Istituto Nazionale per l'Analisi delle Politiche Pubbliche) promuove il corso:
"Metodologia della Peer Review di EQAVET e principali strumenti di autovalutazione nell'IFP".
Sono previste solo due sessioni ad aprile 2026, di 15 partecipanti ciascuna.
Clicca qui per maggiori informazioni oppure consulta il sito www.skillfactory.it.

 Eventi Formativi
Eventi Formativi

-

TECNICO DELLA PROGRAMMAZIONE
Napoli 22/04/2026
-

TonyBuzan Mind Mapping Practitioner for Business
Napoli 05/07/2018
-

IoT e criptovalute, la nuova frontiera del lavoro giovanile, partecipa al Webinar gratuito
27/04/2018
-
PRINCE2® 2017 Practitioner
Napoli 21/06/2018
-
PRINCE2® 2017 Foundation
Napoli 16/07/2018
-
GTD® I&I Sessions
Roma, Milano 01/01/2018
-

Automazione dell'ufficio con SharePoint
Roma 17/04/2017
-

Automazione dell'ufficio con SharePoint
Napoli 03/04/2017
-
Getting Things Done ® Mastering Workflow 1
Napoli 05/07/2018
-
Mind Mapping Practitioner for Students
Napoli 05/07/2018
 Offerte di Lavoro
Offerte di Lavoro
 Post più recenti
Post più recenti
-

Full Stack Developer
07/05/2026
-
1° MAGGIO: FESTA DEL LAVORO E DELLA FORMAZIONE
01/05/2026
-
Operatore Amministrativo Contabile
09/04/2026
-
Tecnico Programmatore: Il Profilo più richiesto dai giovani che frequentano la nostra Academy
17/03/2026
-
6.L'Assicurazione della Qualità nell'IFP
24/01/2026
-
Skill Factory 2025: Un anno di formazione tra "Innovazione (AI), Qualità (EQAVET) e Politiche Attive del Lavoro (PAR GOL)"
30/12/2025
-
10.Intelligenza Artificiale: cosa cambia nel mondo del lavoro
21/12/2025
-
5.L’etica della formazione come responsabilità professionale
13/12/2025
-
4.Buona Formazione: "Come assicurare la Qualità della Formazione"
06/12/2025
-
Corso gratuito di 60 ore per creare le competenze digitali fondamentali (DIGCOMP2.2)
25/09/2025