





-

-

- AULE GRUPPI
-
 Le Tue Aule
Le Tue Aule
-
 I Tuoi Gruppi
I Tuoi Gruppi
-
 Le Tue Selezioni
Le Tue Selezioni
-





 Scheda Azienda
Scheda Azienda Eventi formazione
Eventi formazione Lavora con noi
Lavora con noi
 Richiedi informazioni
Richiedi informazioni
Skill Factory
Categoria: Home
La qualità della formazione inizia dal confronto
![]() Gino Visciano |
Skill Factory - 12/04/2025 11:30:34 | in Home
Gino Visciano |
Skill Factory - 12/04/2025 11:30:34 | in Home
 Nella filiera della formazione professionale (IFP/IFP+), il tema della qualità è sempre più centrale, non solo in ottica di controllo, ma soprattutto come leva di miglioramento continuo e partecipazione. In questo quadro, la Peer Review di EQAVET, si sta affermando come una metodologia innovativa, promossa dalla rete EQAVET e dal National Reference Point (NRP) italiano collocato presso INAPP.
Nella filiera della formazione professionale (IFP/IFP+), il tema della qualità è sempre più centrale, non solo in ottica di controllo, ma soprattutto come leva di miglioramento continuo e partecipazione. In questo quadro, la Peer Review di EQAVET, si sta affermando come una metodologia innovativa, promossa dalla rete EQAVET e dal National Reference Point (NRP) italiano collocato presso INAPP.
I Punti nazionali di riferimento per la qualità dell’Istruzione e della formazione professionale costituiscono i punti di contatto tra il livello europeo e il livello nazionale.
L’Italia è stata tra i primi Paesi europei a costituire il Reference Point: nel 2006 il Ministero del Lavoro, il Ministero dell’Istruzione e la IX Commissione della Conferenza delle Regioni e delle Province autonome hanno incaricato l'INAPP (allora ISFOL) di costituire il National Reference Point.

OBIETTIVI PRINCIPALI DEGLI NRP
Gli obiettivi principali dei National Reference Point sono:
1. informare i principali stakeholder nazionali sulle attività delle Rete europea per la qualità dell’Istruzione e formazione professionale;
2. promuovere iniziative per rafforzare l’uso di metodologie di assicurazione e sviluppo di qualità nell’istruzione e formazione professionale;
3. sviluppare tra gli stakeholder la consapevolezza dei benefici che derivano dall’utilizzo degli strumenti di assicurazione e sviluppo della qualità;
4. coordinare le attività nazionali sull'assicurazione e lo sviluippo della qualità.
Il National Reference Point italiano offre uno spazio di confronto, un tavolo di lavoro, un’attività di analisi di modelli, metodologie e strumenti, anche attraverso l’assistenza tecnica ai Ministeri, alle Regioni, alle Parti sociali ed alle strutture formative per la diffusione della qualità e per l’applicazione delle indicazioni comunitarie quali la Raccomandazione relativa all’istruzione e formazione professionale per la competitività sostenibile, l’equità sociale e la resilienza del 24 novembre 2020 e la Dichiarazione di Osnabrück per il sostegno ai sistemi di istruzione e formazione professionale del 30 novembre 2020.
DICHIARAZIONE DI OSNABRUCK
La Dichiarazione Osnabrück sull'istruzione e la formazione professionale è stata approvata il 30 novembre 2020 da: i ministri responsabili dell'istruzione e della formazione professionale degli Stati membri dell'UE, dei Paesi candidati, dei Paesi dello Spazio economico europeo, dalle parti sociali europee e dalla commissione europea; definisce nuove azioni politiche per il periodo 2021-2025 a integrazione della Raccomandazione del Consiglio sull'istruzione e la formazione professionale per la competitività sostenibile, l'equità sociale e la resilienza.

La Dichiarazione delinea quattro obiettivi da raggiungere attraverso misure a livello nazionale e dell’UE:
a) promuovere la resilienza e l’eccellenza attraverso un’istruzione e una formazione professionale di qualità, inclusiva e flessibile;
b) creare una nuova cultura dell’apprendimento permanente centrata sull'acquisizione di competenze e sulla digitalizzazione;
c) includere la sostenibilità e l’ecosostenibilità (economia verde) nell’IFP/IFP+;
d) rafforzare la dimensione internazionale dell’istruzione e della formazione professionale e di uno spazio europeo dell’istruzione e della formazione.
IL QUADRO EUROPEO DI RIFERIMENTO EQAVET
La Raccomandazione 2020 ribadisce l'importanza del Quadro europeo di riferimento per la garanzia della qualità dell'istruzione e della formazione professionale, noto come EQAVET (European Quality Assurance in Vocational Education and Training), già presente nella Raccomandazione del Parlamento europeo e del Consiglio del 18 giugno 2009, introducendo elementi di novità.

EQAVET costituisce il principale riferimento per sostenere gli Stati membri nel migliorare la qualità dei loro sistemi e per accrescere la trasparenza delle politiche nazionali in materia di istruzione e formazione professionale. La Raccomandazione sottolinea il ruolo del Quadro europeo di riferimento EQAVET come strumento fondamentale per i sistemi nazionali di garanzia della qualità. Tale Quadro di riferimento riguarda l'istruzione e la formazione professionale in tutti gli ambienti di apprendimento (l'erogazione su base scolastica e l'apprendimento basato sul lavoro, compresi i programmi di apprendistato), in tutti i contesti di apprendimento (digitale, in presenza o misto), fornita sia da erogatori pubblici che privati.
EQAVET si basa su un ciclo continuo di miglioramento, ispirato al ciclo di Deming (PDCA - Plan, Do, Check, Act):
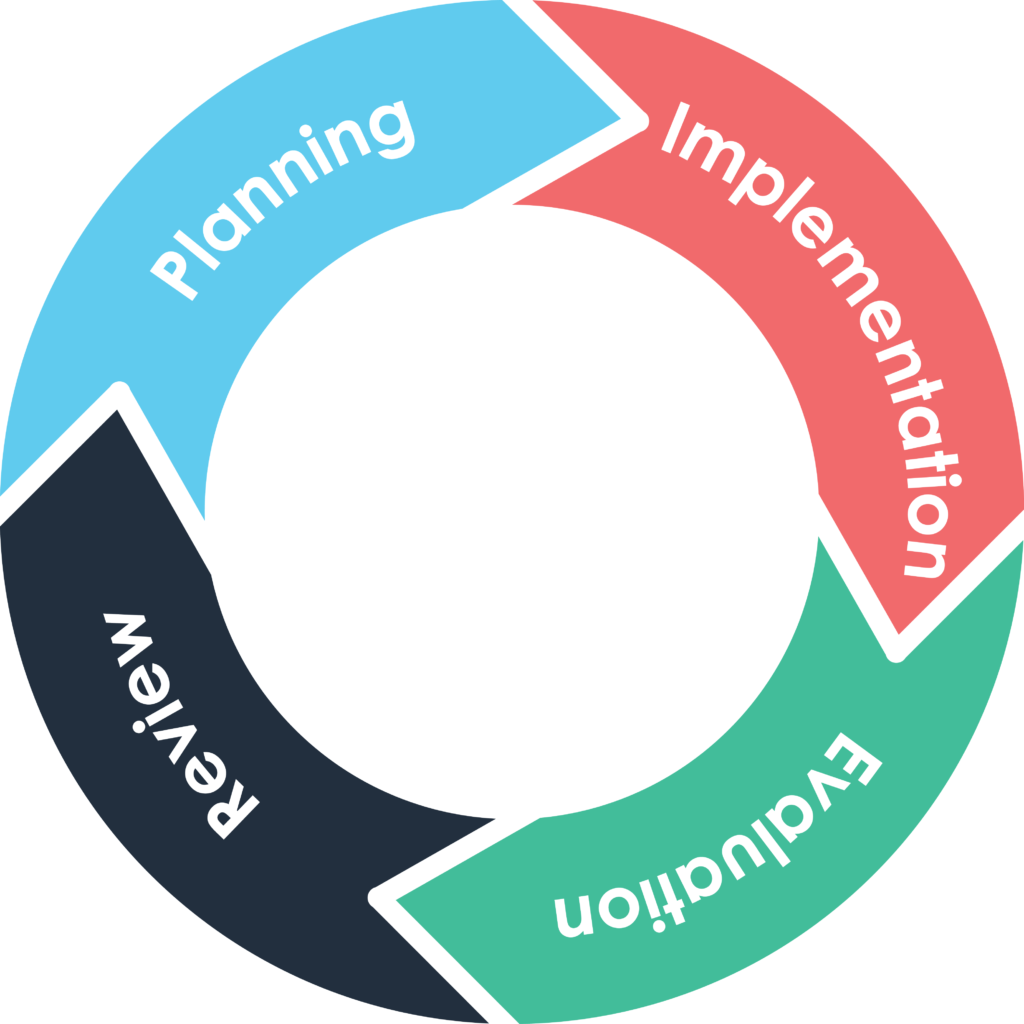
1. pianificazione;
2. attuazione;
3. valutazione;
4. revisione.
Questo ciclo serve a garantire che i sistemi di IFP/IFP+ migliorino nel tempo e che le decisioni siano guidate da evidenze concrete.
I descrittori sono "linee guida qualitative".
Gli indicatori sono "strumenti di misura".
Possono essere applicati all'istruzione e formazione professionale iniziale e continua e sono validi per tutti gli ambienti di apprendimento, scolastico e basato sul lavoro, compresi i programmi di apprendistato.
In particolare, la rete EQAVET, composta dagli NRP si propone di:
- promuovere: l'utilizzo e lo sviluppo del Quadro europeo di riferimento per la garanzia della qualità, dei descrittori e degli indicatori.
- sostenere: un approccio volto a rafforzare la qualità dei sistemi di IFP/IFP+ e ad utilizzare nel modo migliore il Quadro di riferimento, coinvolgendo le parti sociali, le autorità regionali e locali e tutti gli attori interessati.
- sviluppare: la cultura della qualità, sostenendo la valutazione e il miglioramento dei sistemi e degli erogatori di istruzione e formazione professionale.
- favorire: la realizzazione di una dimensione europea per la garanzia della qualità dell'IFP/IFP+.
ORGANIZZAZIONE DEI DESCRITTORI E INDICATORI EQAVET SECONDO IL CICLO PDCA
PLAN – Pianificazione
Definire obiettivi e strategie, predisporre risorse e strumenti.
1. Pertinenza dei sistemi di garanzia della qualità:
a) Quota di erogatori che applicano sistemi di qualità;
b) Quota di erogatori accreditati.
2. Investimento nella formazione di insegnanti e formatori:
a) Quota di insegnanti/formatori che partecipano a formazione;
b) Ammontare dei fondi investiti (anche per competenze digitali).
3. Meccanismi per individuare esigenze del mercato del lavoro:
a) Informazioni sui meccanismi attivi;
b) Prova del loro uso ed efficacia.
4. Sistemi per migliorare l'accesso e fornire orientamento:
a) Informazioni sui sistemi di orientamento;
b) Prova della loro efficacia.
DO – Attuazione
Mettere in pratica le attività pianificate.
5. Tasso di partecipazione ai programmi di IFP/IFP+:
Numero di partecipanti per tipo di programma e criteri individuali.
6. Tasso di completamento dei programmi di IFP/IFP+:
Numero di persone che completano o abbandonano i programmi.
7. Prevalenza di categorie vulnerabili:
a) Percentuale di partecipanti svantaggiati (per età/genere);
b) Tasso di successo delle categorie svantaggiate.
CHECK – Valutazione
Analizzare dati e risultati rispetto agli obiettivi fissati.
8. Tasso di inserimento post-IFP/IFP+:
a) Destinazione dei discenti dopo la formazione;
b) Quota di discenti occupati.
9. Utilizzo delle competenze sul luogo di lavoro:
a) Tipo di occupazione svolta;
b) Soddisfazione di discenti e datori di lavoro;
10. Tasso di disoccupazione:
Secondo criteri individuali.
ACT – Revisione
Apportare miglioramenti sulla base delle evidenze raccolte.
I dati raccolti da CHECK e l’analisi dei risultati rispetto a quanto pianificato in PLAN permettono di:
- Rivedere i meccanismi di qualità;
- Ricalibrare gli investimenti nella formazione dei docenti;
- Adattare i sistemi di orientamento;
- Migliorare i meccanismi di lettura del mercato del lavoro.
In pratica, nella fase ACT si riconsiderano gli elementi del piano iniziale:
- Pertinenza dei sistemi di garanzia della qualità per gli erogatori di istruzione e formazione professionale:
- Investimento nella formazione degli insegnanti e dei formatori:
- Meccanismi per individuare le esigenze di formazione del mercato del lavoro:
- Sistemi utilizzati per migliorare l'accesso all'IFP e fornire orientamenti ai (potenziali) discenti dell'IFP/IFP+:
alla luce dei risultati valutati, per migliorare il ciclo successivo.
LA PEER REVIEW
La Peer Review inserita tra gli strumenti del Piano nazionale per la garanzia della qualità (2017), promosso dal Ministero del Lavoro, dal Ministero dell’Istruzione, dalle Regioni e dalle Parti Sociali, con assistenza tecnica di INAPP. Conferendole un riconoscimento nazionale e strategico, in linea con le indicazioni europee di EQAVET e della Raccomandazione VET del 2020.
La Peer Review è una metodologia di valutazione esterna, qualitativa e volontaria, condotta tra “pari” – ossia professionisti di altri enti di formazione – che analizzano e offrono un feedback costruttivo su processi, pratiche e risultati di un’organizzazione formativa.
A differenza delle verifiche ispettive o degli audit formali, la Peer Review nasce in un contesto di fiducia e dialogo, e mira a promuovere apprendimento reciproco e miglioramento continuo.
Possiamo definire la Peer Review come:
- Qualitativa: si basa su osservazioni, interviste e documentazione, con il supporto di dati quantitativi.
- Flessibile: può riguardare l’intera organizzazione o singole aree (es. docenza, progettazione, inclusione).
- Economica: poco onerosa da implementare, adatta anche a contesti con risorse limitate.
- Adattabile: ogni struttura può declinarla secondo i propri obiettivi e contesto operativo.
- Partecipativa: è percepita come “valutazione leggera” e costruttiva, con alto grado di accettazione.
I principali punti di forza sono:
1. Si può inserire e integrare con le strategie e le attività per l’assicurazione di qualità già in corso (autovalutazione, accreditamento, certificazione ISO);
2. E’ una metodologia di facile applicazione anche per i “principianti” della valutazione. Attua una combinazione di valutazione interna ed esterna e così promuove un virtuoso intreccio tra controllo di qualità e miglioramento continuo;
3. E’ un’attività poco dispendiosa;
4. Prevede procedure e obiettivi flessibili che si prestano ad essere adattati a contesti differenti: la valutazione dei Pari può riferirsi ad una o più aree di qualità o all’intera organizzazione;
5. Ha un elevato grado di accettazione da parte della struttura valutata perché percepita come forma di valutazione “leggera”;
6. E’ occasione di apprendimento reciproco per tutti i partecipanti.
La metodologia Peer Review di EQAVET può essere applicata sia a livello di erogatori, sia a livello di sistemi dell'IFP/IFP+ e prevede le quattro fasi:
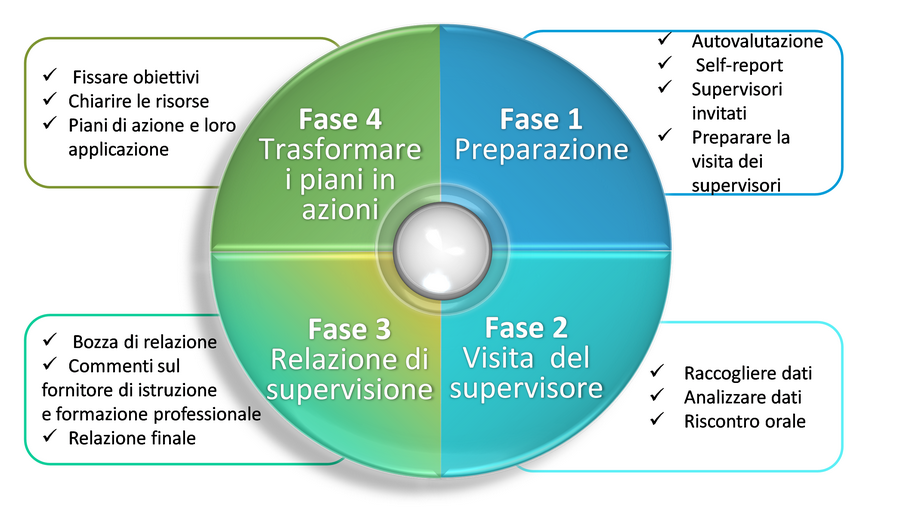
1. Nella prima fase, l'istituzione che promuove e ospita la Peer Review effettua un'autovalutazione e redige il rapporto di autovalutazione (Self-assessment report), individua i Pari e pianifica la visita.
2. Nella seconda fase si svolge la visita dei Pari che costituisce l'attività centrale della metodologia. A partire dall'analisi del rapporto di autovalutazione, i Pari si riuniscono presso l'istituzione e acquisiscono ulteriori informazioni utili alla valutazione attraverso focus group, interviste e incontri. Durante la visita, oltre ad approfondire le aree, i descrittori e gli indicatori di qualità, i Pari forniscono anche dei feedback verbali all'istituzione ospitante.
3. Nella terza fase, successiva alla visita, i Pari elaborano il rapporto finale della valutazione (Peer Review report) e lo condividono con l'istituzione ospitante.
4. La quarta fase è di importanza cruciale per il miglioramento della qualità: i risultati e le raccomandazioni derivanti dalla Peer Review confluiscono in un piano di azione e di attuazione.
La Peer Review rappresenta un'opportunità concreta per rendere la valutazione non solo un adempimento, ma un processo generativo, in cui la qualità si costruisce attraverso il dialogo tra professionisti, il confronto tra pratiche, e l’analisi condivisa di ciò che funziona. Affinché questa metodologia valutativa si diffonda, serve un impegno congiunto: formazione, cultura valutativa e reti tra enti.
IL RUOLO DEI PARI
I pari sono professionisti del settore (formazione, istruzione, politiche attive del lavoro) che non fanno parte dell’organizzazione valutata, ma che condividono esperienze, contesto o funzione simile.

In pratica, possono essere:
- Formatori o coordinatori didattici di altri enti accreditati;
- Dirigenti scolastici o responsabili di CFP/ITS;
- Esperti di qualità o valutatori accreditati (non ispettivi!);
- Tecnici di Regioni, enti locali, INVALSI, INDIRE, INAPP;
- Rappresentanti delle parti sociali (con esperienza formativa);
- Ex partecipanti o imprese partner di progetti simili.
Il concetto di parità riguarda l'esperienza e il ruolo rispetto a coloro che sono valutati.
Qual è il ruolo dei pari nella Peer Review?
I pari agiscono come valutatori esterni, ma in una logica collaborativa, formativa e non giudicante.
Il loro ruolo si articola in più funzioni:
1. Osservatori e ascoltatori attivi:
Raccolgono dati e osservazioni durante la visita all’organizzazione (lezioni, riunioni, colloqui);
Analizzano documenti, piani formativi, strumenti di valutazione.
2. Facilitatori di dialogo:
Promuovono uno scambio aperto, paritetico, fondato sulla fiducia;
Creano un clima costruttivo per discutere punti di forza e aree di miglioramento.
3. Restituiscono un feedback mirato:
Elaborano una sintesi strutturata (verbale o scritta), chiara e motivata;
Offrono spunti di riflessione, suggerimenti e proposte (non giudizi o prescrizioni).
4. Apprendono a loro volta:
Riflettono anche sulla propria pratica professionale, apprendendo da ciò che osservano;
Rafforzano la propria competenza valutativa e ne ricavano benefici anche per il loro ente di appartenenza.
La figura del pari è determinante perché “credibile “ in quanto come valutatore opera a fianco del valutato, non imponendo nessun giudizio ma eventualmente proponendo cambiamento. Nell’ambito dell’apprendimento tra pari si possono sviluppare delle reti professionali che si manterranno anche dopo la fine della peer review.
Nell'ambito della Peer Review nella formazione professionale, i pari sono professionisti esterni all'organizzazione valutata, operanti in contesti simili, con esperienza e competenze specifiche nel settore. Il loro ruolo è fornire una valutazione costruttiva e obiettiva, contribuendo al miglioramento continuo della qualità.
LA FORMAZIONE DEI PARI
- Metodologia della Peer Review: comprensione dei principi, delle fasi e degli strumenti utilizzati nel processo di valutazione tra pari;
- Quadro europeo EQAVET: approfondimento del Quadro Europeo di Assicurazione della Qualità per l'Istruzione e la Formazione Professionale e della sua applicazione pratica.
- Competenze pratiche: sviluppo delle abilità necessarie per condurre interviste, analizzare documenti, osservare attività formative e fornire feedback costruttivi.
I miei ringraziamenti vanno a Laura Evangelista Coordinatrice National Reference Point EQAVET per il supporto tecnico offerto per scrivere l'articolo e a tutti i "Pari" che svolgono un ruolo fondamentale per garantire e migliorare la qualità della formazione nella filiera della formazione professionale (IFP/IFP+).
Per saperne di più, visita il sito del Reference Point Nazionale Qualità - INAPP:
🌐 www.inapp.org/eqavet
Riferimenti:
https://oa.inapp.gov.it/server/api/core/bitstreams/cb420a20-309b-4393-8427-2ca3b87755a7/content
https://oa.inapp.org/xmlui/bitstream/handle/20.500.12916/3594/INAPP_Eqavet_brochure_2022.pdf?sequence=1&isAllowed=y
https://oa.inapp.org/xmlui/bitstream/handle/20.500.12916/3593/INAPP_La_rete_europea_Eqavet_e_il_NRP_italiano_2022.mp4?sequence=1&isAllowed=y
https://youtu.be/Okgz-MfZuAk
PROSSIMI EVENTI

Seguici su: www.skillfactory.it

7.Intelligenza Artificiale: Come creare una chatbot per conversare con LLAMA3
![]() Gino Visciano |
Skill Factory - 15/03/2025 16:57:31 | in Home
Gino Visciano |
Skill Factory - 15/03/2025 16:57:31 | in Home
In questo articolo vi spiegherò come creare una chatbot per conversare con Llama3 attraverso Ollama.
Potete utilizzare la chatbot, sia per conversare con Llama3, sia per imparare l'inglese, perché Llama3 oltre a rispondere in italiano, aggiunge anche la traduzione in lingua inglese.
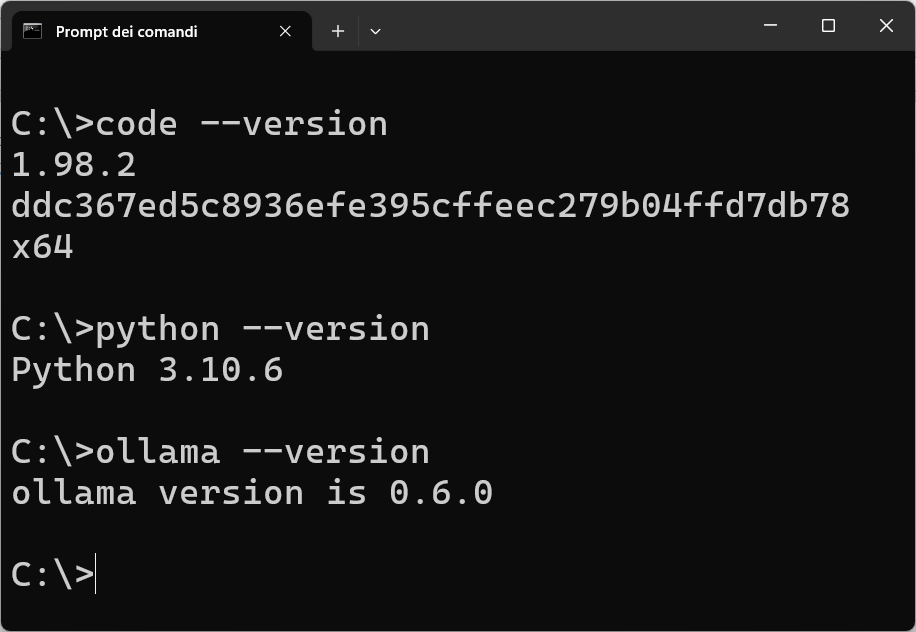
Per creare la chatbot, servono gli strumenti seguenti: Visual Studio Code, Python e Ollama, quindi, assicuratevi che siano stati installati correttamente sul vostro computer, con i comandi seguenti:
Llama 3 è un modello linguistico di grandi dimensioni (LLM) sviluppato da Meta AI, progettato per comprendere e generare testo in linguaggio naturale.
E' disponibile in tre versioni con differenti quantità di parametri: 8 miliardi (8B), 70 miliardi (70B) e 400 miliardi (400B). Le versioni 8B e 70B sono open-source e accessibili al pubblico, mentre la versione 400B è attualmente in fase di addestramento.
L'immagine seguente mostra come potete visualizzare le caratteristiche della versione di Llama3 installata sul vostro computer:
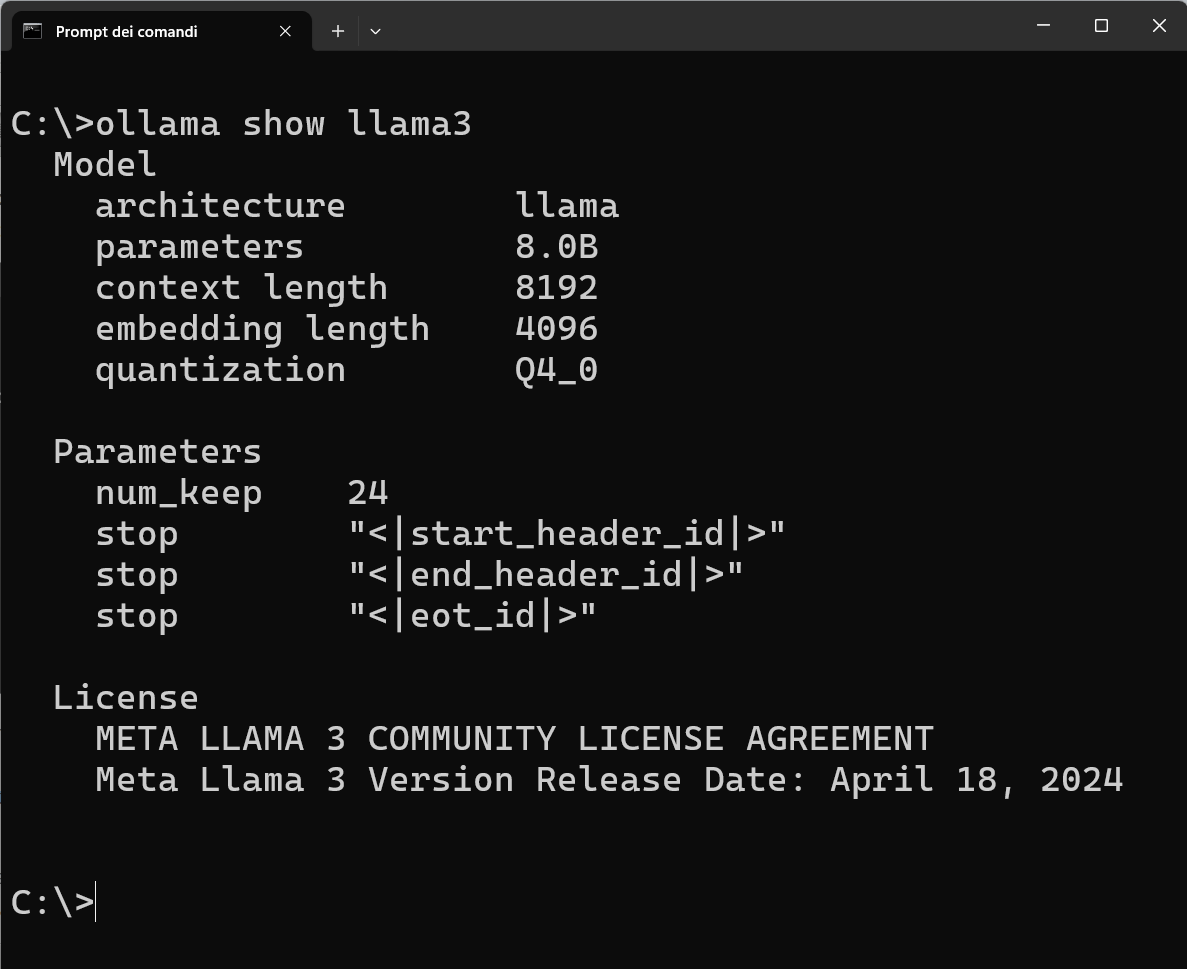
Llama 3 è stato addestrato utilizzando dati online di alta qualità fino a dicembre 2023, impiegando tecniche di filtraggio avanzate per garantire l'eccellenza dei dati di addestramento. Le sue applicazioni spaziano dalla generazione di contenuti alla traduzione multilingue, fino all'intelligenza artificiale conversazionale.
In termini di prestazioni, Llama 3 ha ottenuto punteggi elevati in vari benchmark, superando modelli come GPT-3.5 in alcune metriche.
Per eseguire Llama3 su un computer locale serve Ollama.
Ollama è un framework leggero ed estensibile che consente di eseguire modelli di linguaggio di grandi dimensioni (LLM) localmente, fornendo un'API per creare applicazioni che comunicano con il modello associato. Per comunicare con Llama3 attraverso l'API di Ollama, installato sul vostro computer, dovete usare il protocollo applicativo HTTP e collegarvi alla porta 11434, come mostra il link seguente:
http://localhost:11434/api/generate.
Per creare il Chatbot con Python servono le librerie: tkinter, requests e json, che potete caricare con il codice seguente:
import tkinter as tk
from tkinter import scrolledtext
import requests
import json
La libreria tkinter è utilizzata nel programma per creare l'interfaccia grafica (GUI) del Chatbot.
La libreria requests è utilizzata per gestire la comunicazione HTTP con l'API di Ollama, che esegue il modello Llama3.
La libreria json nel programma serve per due motivi principali:
1.Decodifica delle risposte: Quando ricevi una risposta dal server Ollama, i dati arrivano come stringhe in formato JSON. La funzione json.loads() è utilizzata per convertire queste stringhe in oggetti Python (come dizionari), rendendo possibile accedere ai dati tramite chiavi;
2.Serializzazione dei dati da inviare: Quando invii la richiesta POST a Ollama, il payload viene passato come oggetto Python (di tipo dizionario). Il parametro json=payload nella richiesta fa sì che Python usi automaticamente la libreria json per convertire l'oggetto in una stringa JSON da inviare.
IMPOSTAZIONE DELLA GUI DELLA CHATBOT
1. Creazione della Finestra Principale
root = tk.Tk()
root.title("Llama3 Chatbot")
root.configure(bg='white')
tk.Tk(): Crea la finestra principale dell'applicazione.
root.title("Llama3 Chatbot"): Imposta il titolo della finestra.
root.configure(bg='white'): Imposta lo sfondo della finestra di colore bianco.
2. Area di Visualizzazione della Chat
chat_log = scrolledtext.ScrolledText(root, wrap=tk.WORD, width=60, height=20, bg='white', fg='black', bd=0, relief='flat')
chat_log.pack(padx=10, pady=10)
scrolledtext.ScrolledText: Crea una casella di testo con una barra di scorrimento automatica.
wrap=tk.WORD: Le parole non vengono spezzate a metà quando il testo raggiunge il bordo.
width e height: Definiscono la dimensione del campo di testo.
bg='white' e fg='black': Impostano i colori di sfondo e del testo.
bd=0 e relief='flat': Rendono il bordo della casella piatto e senza spessore.
pack(padx=10, pady=10): Posiziona il widget nella finestra con un margine di 10 pixel.
3. Contenitore per l'Input dell'Utente
user_input_frame = tk.Frame(root, bg='white')
user_input_frame.pack(padx=10, pady=(0, 10))
tk.Frame: Crea un contenitore per raggruppare i widget di input e il pulsante di invio.
bg='white': Imposta il colore di sfondo del frame.
pack(padx=10, pady=(0, 10)): Posiziona il frame con un margine superiore di 0 e inferiore di 10 pixel.
4. Campo di Inserimento Testo
user_input = tk.Entry(user_input_frame, width=50, bg='white', fg='black', bd=1, relief='solid', highlightthickness=1, highlightbackground='#d9d9d9', highlightcolor='#4a90e2')
user_input.pack(side=tk.LEFT, padx=(0, 5), ipady=5, ipadx=5)
tk.Entry: Crea un campo per l'inserimento di testo da parte dell'utente.
width=50: Imposta la larghezza del campo di testo.
bd=1 e relief='solid': Definiscono un bordo sottile e solido.
highlightthickness, highlightbackground, highlightcolor: Configurano l'aspetto del bordo di evidenziazione.
pack(side=tk.LEFT, padx=(0, 5), ipady=5, ipadx=5): Posiziona il campo a sinistra del frame con un po' di padding.
5. Pulsante di Invio
send_button = tk.Button(user_input_frame, text="Invia", command=send_message, bg='black', fg='white', activebackground='#333333', activeforeground='white', bd=0, padx=10, pady=5, relief='flat')
send_button.pack(side=tk.RIGHT)
tk.Button: Crea un pulsante etichettato "Invia".
command=send_message: Associa il pulsante alla funzione send_message che verrà eseguita al click (nota: questa funzione non è definita nel codice fornito).
bg e fg: Definiscono i colori di sfondo e del testo del pulsante.
activebackground e activeforeground: Colori quando il pulsante è attivo.
bd=0 e relief='flat': Rendono il bordo del pulsante piatto e senza spessore.
pack(side=tk.RIGHT): Posiziona il pulsante a destra del frame.
Per avviare l'interfaccia viene utilizzata la funzione main():
def main():
root.mainloop()
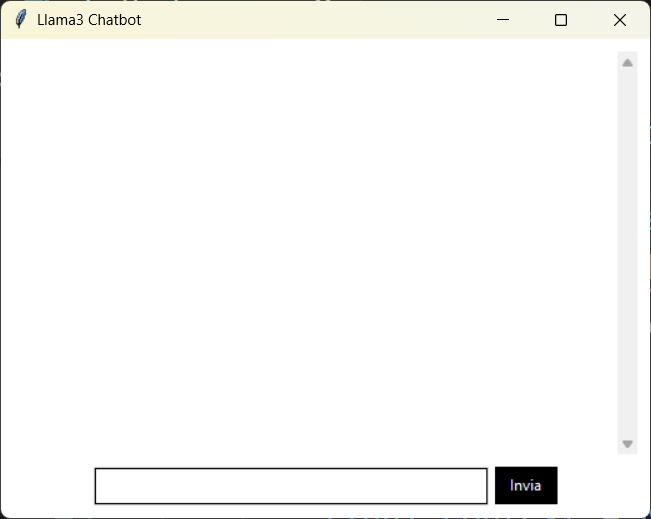
L'immagine seguente mostra coma appare la GUi del Chatbot in esecuzione:
COME INVIARE LE RICHIESTE AL SERVER OLLAMA
1. Dichiarazione della Funzione e Variabili Globali
La funzione send_message gestisce l'invio di un messaggio dell'utente alla chatbot e visualizza la risposta generata da Llama3 tramite Ollama.
def send_message():
global chat_history, chat_context
global chat_history, chat_context: Indica che le variabili chat_history e chat_context sono globali.
chat_history: Conserva l'intera cronologia della chat.
chat_context: Potrebbe essere utilizzata per mantenere il contesto tra le richieste (utile per i modelli di AI che gestiscono conversazioni complesse).
2. Lettura del Messaggio dell'Utente
user_message = user_input.get()
if user_message.strip() == "":
return
user_input.get(): Recupera il testo inserito dall'utente nel campo di input.
user_message.strip() == "": Controlla se il messaggio è vuoto o contiene solo spazi. Se sì, la funzione termina senza fare nulla (return).
3. Visualizzazione del Messaggio dell'Utente nella Chat
chat_log.insert(tk.END, f"You: {user_message}\n")
user_input.delete(0, tk.END)
chat_log.insert(tk.END, f"You: {user_message}\n"): Inserisce il messaggio dell'utente nella finestra di chat.
user_input.delete(0, tk.END): Pulisce il campo di input, pronto per un nuovo messaggio.
4. Aggiornamento della Cronologia della Chat
chat_history += f"You: {user_message}\n"
Aggiunge il messaggio dell'utente alla cronologia della chat, in modo che il modello abbia il contesto completo della conversazione.
5. Invio del Messaggio a Llama3 tramite Ollama
response, chat_context = get_llama3_response(chat_history, chat_context)
get_llama3_response(): Chiama una funzione (presumibilmente definita altrove) che:
Riceve la cronologia della chat e il contesto attuale.
Restituisce una risposta generata dal modello Llama3 e un nuovo contesto aggiornato.
response: La risposta generata da Llama3.
chat_context: Il contesto aggiornato che sarà utilizzato nelle conversazioni future.
6. Visualizzazione della Risposta del Modello
chat_log.insert(tk.END, f"Llama3: {response}\n")
Visualizza la risposta del modello nel registro della chat.
7. Aggiornamento Finale della Cronologia
chat_history += f"Llama3: {response}\n"
Aggiunge la risposta del modello alla cronologia per mantenere il contesto coerente nelle interazioni future.
COME GESTIRE LE RISPOSTE RICEVUTA DAL SERVER OLLAMA
La funzione get_llama3_response invia una richiesta POST all'API di Ollama per generare una risposta basata su un prompt e un contesto di conversazione. Gestisce anche lo streaming della risposta e aggiorna il contesto per le interazioni successive.
1. Argomenti della funzione
def get_llama3_response(prompt, context):
prompt: Il testo della conversazione, che include la cronologia dei messaggi.
context: Informazioni aggiuntive per mantenere la coerenza del dialogo (opzionale).
1. Preparazione del Payload
try:
payload = {"prompt": prompt, "model": "llama3"}
if context:
payload["context"] = context
payload: Un dizionario contenente i dati da inviare all'API.
"prompt": Il testo della conversazione fino a quel momento.
"model": "llama3": Specifica il modello da utilizzare.
Se il context è disponibile, viene aggiunto per aiutare il modello a mantenere la coerenza della conversazione.
2. Invio della richiesta POST all'API
response = requests.post(
"http://localhost:11434/api/generate",
json=payload,
stream=True
)
requests.post: Esegue una richiesta HTTP POST verso l'API locale di Ollama.
json=payload: Invia i dati della richiesta in formato JSON.
stream=True: Indica che la risposta verrà trasmessa in streaming, utile per ricevere i dati in tempo reale.
3. Gestione della Risposta
full_response = ""
final_context = None
full_response: Variabile per accumulare la risposta completa del modello.
final_context: Variabile per memorizzare il contesto aggiornato, se fornito.
4. Elaborazione della Risposta in Streaming
for line in response.iter_lines():
if line:
data = json.loads(line.decode('utf-8'))
full_response += data.get("response", "")
if data.get("done") and "context" in data:
final_context = data["context"]
response.iter_lines(): Itera sulle righe della risposta in streaming.
json.loads(): Converte ogni linea JSON in un dizionario Python.
data.get("response", ""): Estrae la parte di testo generata e la aggiunge a full_response.
data.get("done"): Verifica se la generazione della risposta è completata.
"context" in data: Se il contesto aggiornato è disponibile, lo salva in final_context.
5. Restituzione del Risultato
return full_response or "Nessuna risposta ricevuta.", final_context
Restituisce la risposta completa.
Se la risposta è vuota, ritorna un messaggio di default: "Nessuna risposta ricevuta.".
Fornisce anche il final_context aggiornato.
6. Gestione degli Errori
except Exception as e:
return f"Errore di connessione: {e}", context
Se si verifica un errore (come problemi di connessione o di decodifica), viene restituito un messaggio di errore insieme al contesto originale.
Per visualizzare il codice Python completo della chatbot clicca qui.
Per eseguire il codice Python della chatbot, copialo e incollalo in Visual Studio Code.
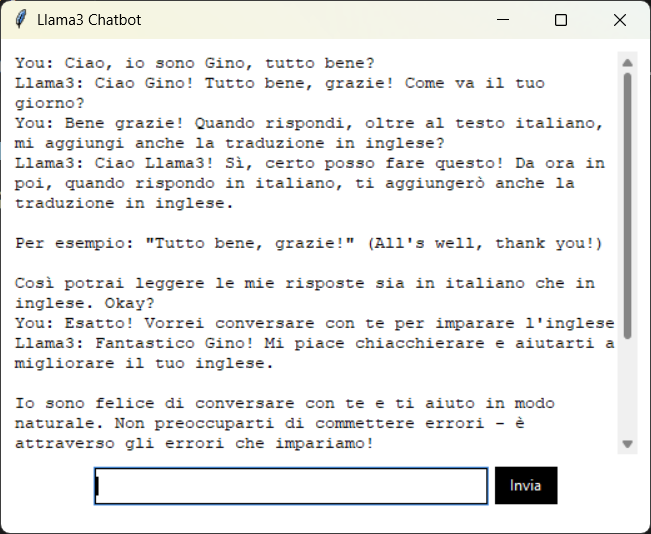
L'immagine seguente mostra un esempio di conversazione con Llama3, utilizzando la nostra chatbot:
Nel prossimo articolo vedremo un semplice esempio di fine tuning per addestrare Llama3.
1.Intelligenza Artificiale: se la conosci non la temi
2.Intelligenza Artificiale: i modelli linguistici di grandi dimensioni
3.Intelligenza Artificiale: le reti neurali artificiali
4.Intelligenza Artificiale: tipi di reti neurali artificiali
5.Intelligenza Artificiale: IA Generativa
6.Intelligenza Artificiale: modelli pre-addestrati di IA locali
6.Intelligenza Artificiale: Modelli pre-addestrati di IA locali (Prima parte)
![]() Gino Visciano |
Skill Factory - 09/02/2025 21:00:03 | in Home
Gino Visciano |
Skill Factory - 09/02/2025 21:00:03 | in Home
 Un modello pre-addestrato d'Intelligenza Artificiale locale è un modello che può essere installato ed eseguito su qualunque computer o server.
Un modello pre-addestrato d'Intelligenza Artificiale locale è un modello che può essere installato ed eseguito su qualunque computer o server.
Questi modelli possono essere scaricati da diverse piattaforme specializzate, la più conosciuta è Hagging Face.
Hugging Face è una piattaforma che offre una vasta gamma di strumenti e risorse per sviluppatori, ricercatori e appassionati di IA. E' molto popolare perché fornisce modelli pre-addestrati e strumenti per l'elaborazione del linguaggio naturale (NLP). Questi modelli possono essere utilizzati per diverse attività come la traduzione automatica, la generazione di testo, l'analisi del sentiment e molto altro ancora.
Gli LLM installati localmente possono essere gestiti con gli strumenti seguenti:
1) OLLAMA
2) LM STUDIO
3) PYTHON
COME LAVORARE CON UN MODELLO PRE-ADDESTRATO LOCALE UTILIZZANDO OLLAMA
Prima di tutto dovete eseguire il download di OLLAMA collegandovi all'indirizzo:
come mosta l'immagine seguente:

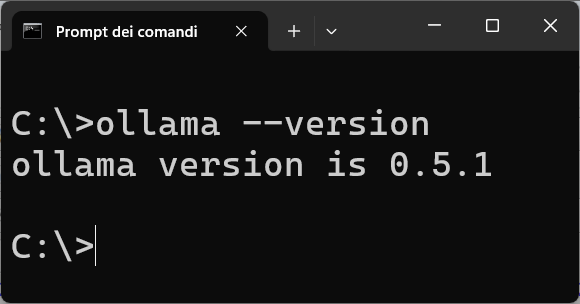
Dopo il download per verificare se OLLAMA è stato installato correttamente eseguite il comando:
ollama --version
Adesso potete caricare il modello pre-addestrato da usare localmente. Vi suggerisco di utilizzare LLAMA3 prodotto da Meta, un modello con 8 miliardi di parametri.
Per installare LLAMA3 eseguite il comando:
ollama pull llama3
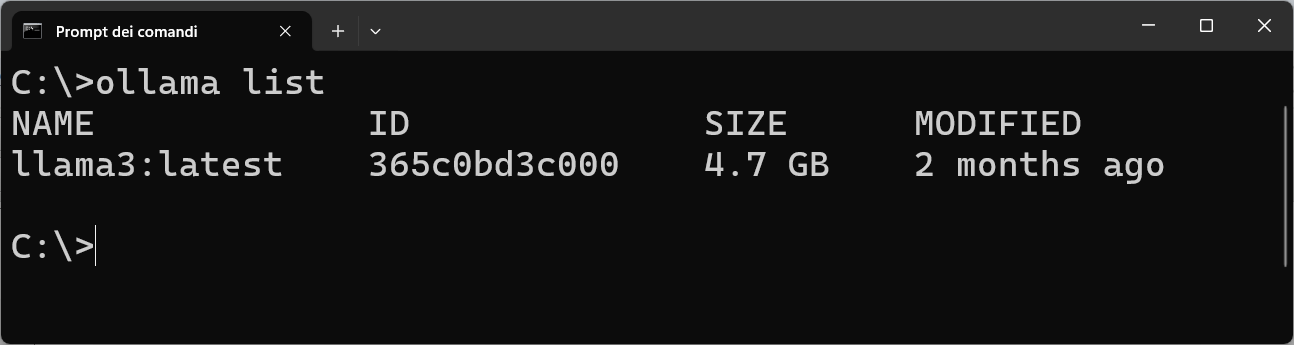
Per verificare se il modello è stato caricato correttamente dovete eseguire il comando:
ollama list
Per visualizzare le caratteristiche del modello appena caricato usate il comando:
ollama show llama3
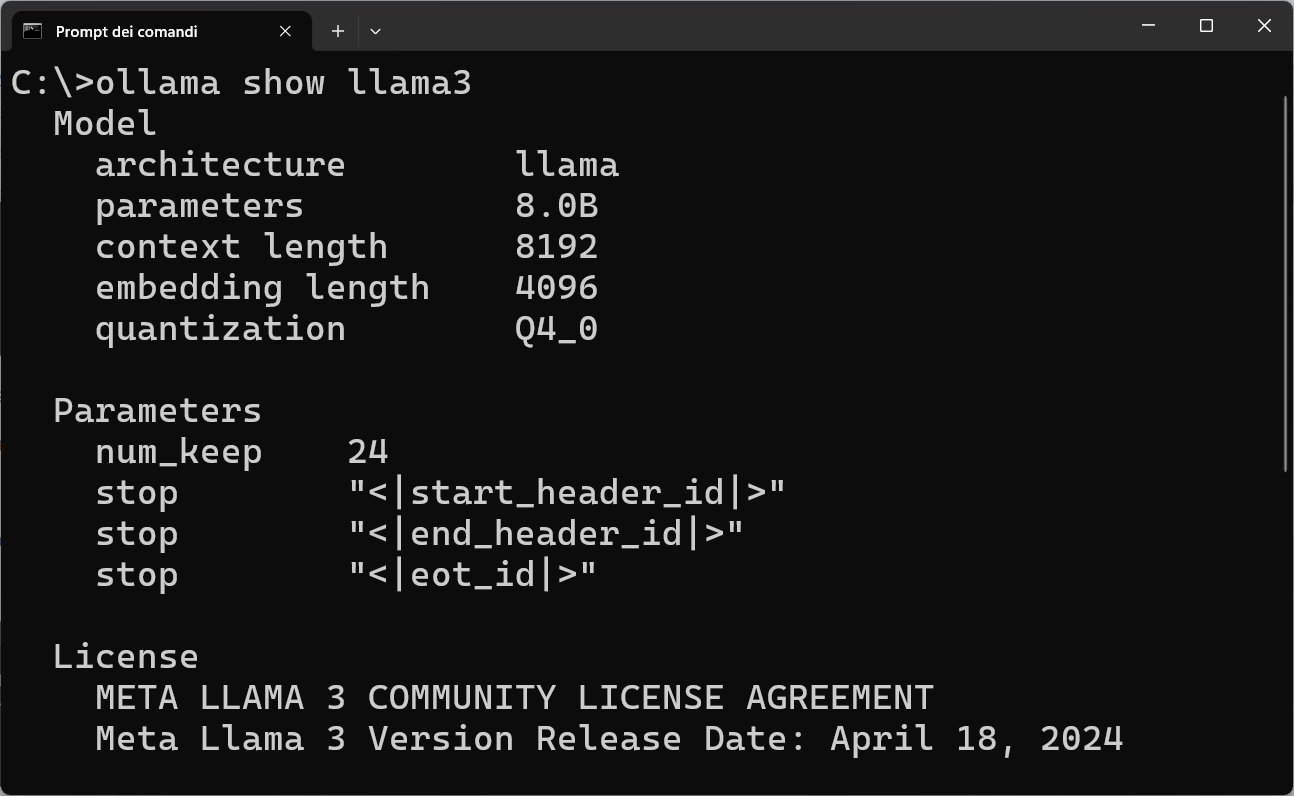
Adesso potete attivare il prompt per porre domande al modello con il comado:
ollama run llama3
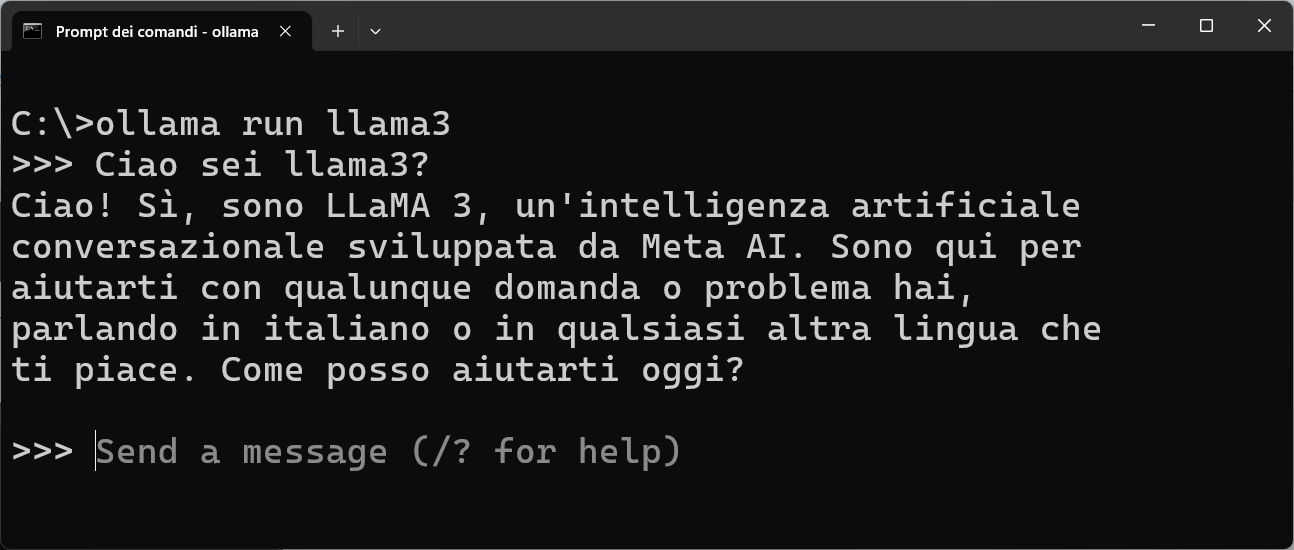
Per conoscere i comandi disponibili usate il comando:
/?
Potete chiudere la sessione corrente con il comando:
/bye
COME LAVORARE CON UN MODELLO PRE-ADDESTRATO LOCALE UTILIZZANDO LM STUDIO
Potete eseguire il download di LM STUDIO collegandovi all'indirizzo:
Dopo il download eseguite il file:

per installarlo.
Quando avviate LM Studio appare la seguente interfaccia grafica:
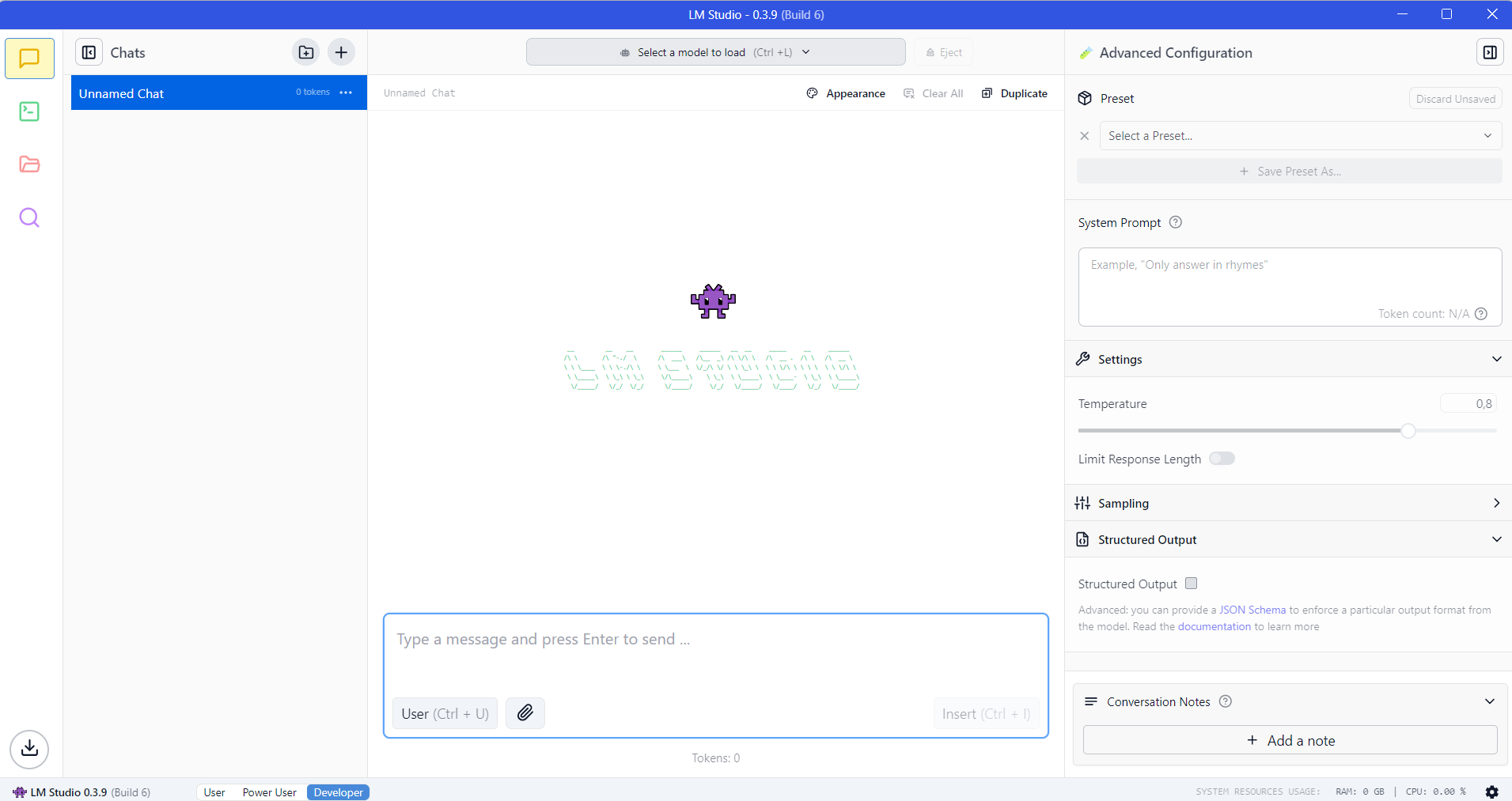
Per caricare il modello dovete cliccare prima sull'icona a sinistra "My Models":
poi successivamente dovete cliccare sulla lente d'ingrandimento che appare al cenrro della schermata:

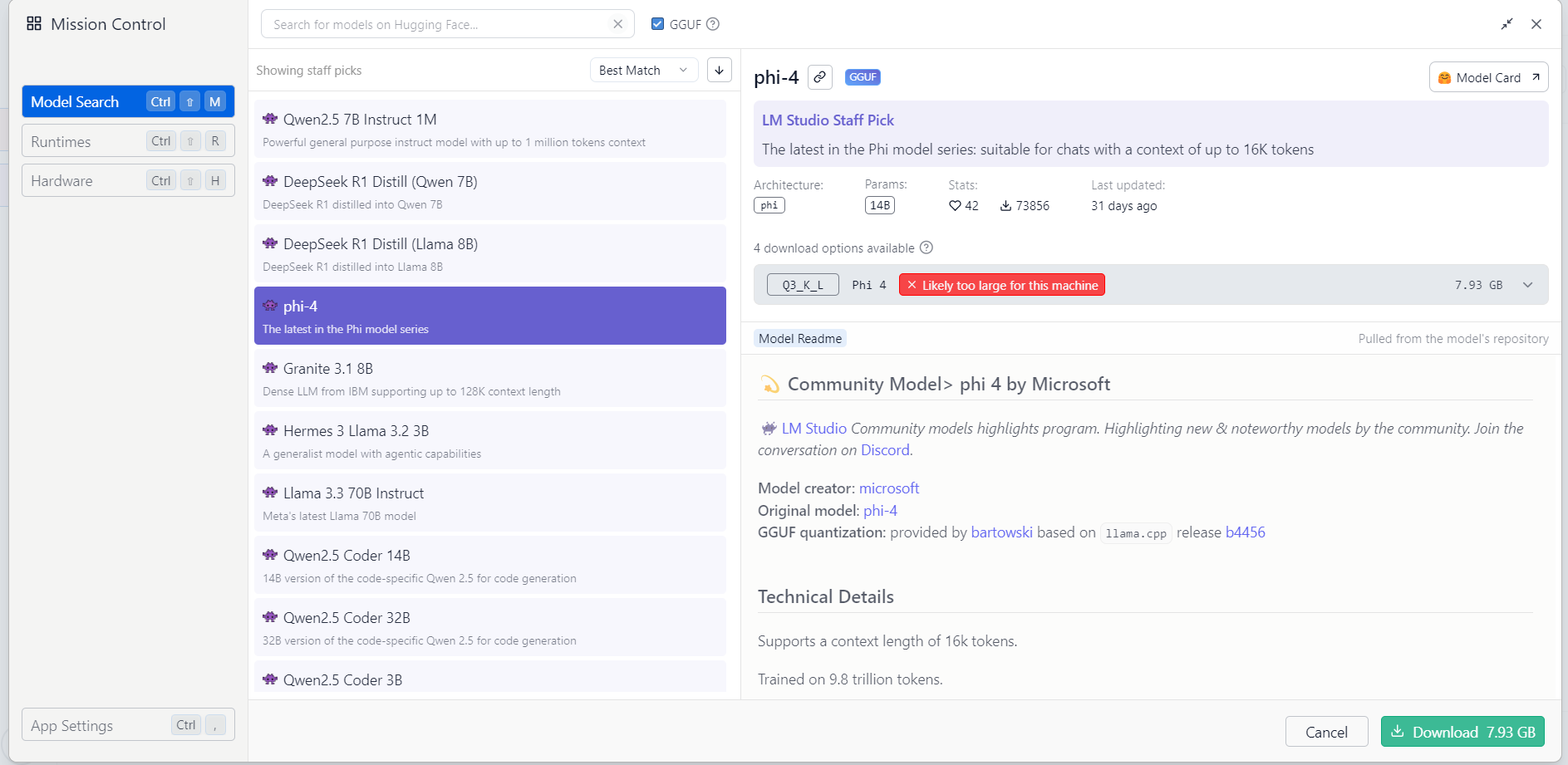
Dopo questa operazione potete scegliere il modello da caricare, selezionandolo e cliccando sul pulsante Download.
Nell'immagine seguente vi mostro come caricare il modello PHI-4 di Microsoft, con 14 miliardi (14B) di parametri.
Dopo il download e il caricamento del modello scelto, tornate alla chat e utilizzate il prompt per porgli le domande.
L'immagine seguente descrive l'area chat di LM Studio.
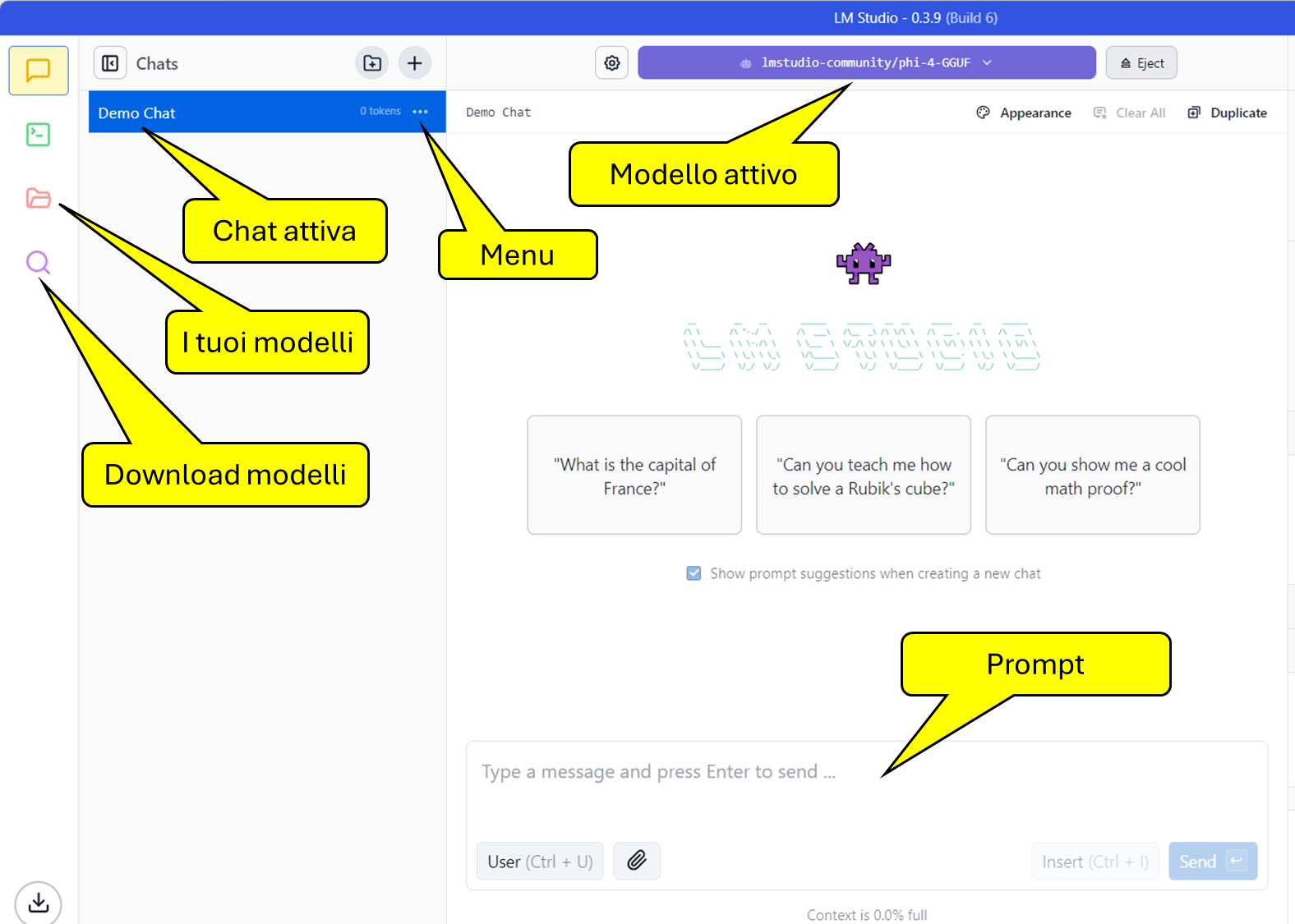
Quando usate la chat di LM Studio assicuratevi sempre di aver caricato il modello che volete utilizzare.
Per caricare uno dei modelli disponibili, cliccate sul pulsante "Select a model to load" o usate i tasti Crtl + L:

scegliete il modello da caricare, selezionandolo con il puntatore del mouse:
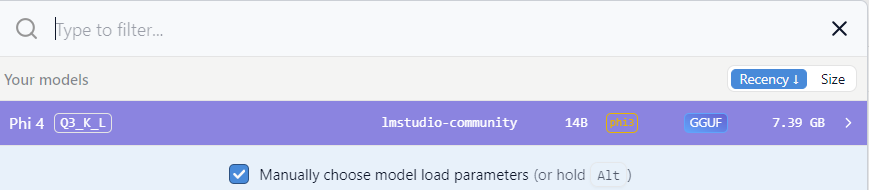
e infine cliccare sul pulsante "Load Model":
Dopo aver caricato il modello potete porgli le domande utilizzando il prompt della chat, come mostra l'esempio seguente:

You
Ciao, sei phi?
Assistant phi-4
Sì, sono qui per aiutarti! Come posso esserti d'aiuto oggi? Se hai delle domande o qualcosa di specifico su cui vorresti discutere, fammelo sapere. 😊
Nel prossimo articolo creeremo una chatbot per comunicare con LLAMA3 attraverso OLLAMA.
1.Intelligenza Artificiale: se la conosci non la temi
2.Intelligenza Artificiale: i modelli linguistici di grandi dimensioni
3.Intelligenza Artificiale: le reti neurali artificiali
4.Intelligenza Artificiale: tipi di reti neurali artificiali
5.Intelligenza Artificiale: IA Generativa
7.Intelligenza Artificiale: come creare una chatbot per conversare con Llama3
Vuoi qualificarti per entrare nel modo del lavoro?
Presso la nostra Academy delle Professioni Digitali, con il programma PAR GOL puoi partecipare ai seguenti corsi di formazione gratuiti di 300 ore, con 90 ore di tirocinio aziendale:

2. Recati al Centro Per l'Impiego (CPI) di competenza per richiedere l'adesione al Programma GOL.
3. Comunica all'operatore del CPI il nome ed il codice identificativo del corso scelto.
Se hai bisogno di assistenza o informazioni ci puoi anche contattarci ai seguenti recapiti:
Telefono: 08118181361
Cellulare: 327 087 0141
E-mail: segreteria@skillfactory.it
oppure puoi prenotare un appuntamento presso la nostra sede al Centro Direzionale di Napoli E2 scala A 1° piano.
2025: "Sviluppo Software", "Amministrazione aziendale" e "Turismo Digitale", sono questi gli ambiti di qualifica professionale PAR GOL scelti dalla Skill Factory, per creare nuovi posti di lavoro
![]() Gino Visciano |
Skill Factory - 07/01/2025 15:22:22 | in Home
Gino Visciano |
Skill Factory - 07/01/2025 15:22:22 | in Home

Quest'anno la strategia della Skill Factory per favorire l'inserimento dei giovani nel mondo del lavoro, punta su tre ambiti di qualifica professionale PAR GOL specifici:
1. Sviluppo Software: Programmatori, Tester, Analisti Funzionali e Sistemisti;
(Corso 10774 di 320 ore in presenza presso la nostra Academy di Napoli, con qualifica professionale EQF 5).
2. Amministrazione aziendale: Esperti di office automation, Esperti di CRM, Esperti di Contabilità e finanza, Esperti di gestione risorse umane;
(Corso 10778 di 300 ore a distanza, con qualifica professionale EQF 5).

"SEGRETARIO-COORDINATORE AMMINISTRATIVO"
Il programma PAR GOL (Garanzia di Occupabilità dei Lavoratori) è attuato dalle Regioni e Province autonome sulla base dei Piani di attuazione regionali (PAR).
È un'azione di riforma prevista dal PNRR (Piano Nazionale di Ripresa e Resilienza) e ha l'obiettivo di riqualificare i servizi di politica attiva del lavoro.
Mira a ridisegnare i servizi per il lavoro per favorire la formazione e l'inserimento lavorativo delle persone. Nel 2025 coinvolgerà oltre 3 milioni di disoccupati e inoccupati, una grande opportunità anche per i giovani che non studiano e non lavorano, che rientrano nella categoria NEET (Not in Education, Employment, or Training). I giovani NEET in Italia sono circa 2 milioni.
Il programma GOL offre la possibilità di accedere a diversi corsi di formazione gratuiti, specificamente progettati per potenziare le competenze dei lavoratori, agevolarne la riqualificazione e favorire lo sviluppo del potenziale per l’inserimento o il reinserimento nel mercato del lavoro.
Questi corsi coprono una vasta gamma di settori e competenze, consentendo ai partecipanti di acquisire la abilità richieste dalle aziende.
Oltre alla formazione gratuita, è prevista anche una indennità di partecipazione e il rilascio di una Qualifica Professionale Europea (EQF).
Per approfondire l'argomento della Qualifica Professionale Europea (EQF), clicca qui.

Se hai bisogno di assistenza o informazioni puoi contattarci ai seguenti recapiti:
Telefono: 08118181361
Cellulare: 327 087 0141
E-mail: segreteria@skillfactory.it
oppure puoi prenotare un appuntamento presso la nostra sede al Centro Direzionale di Napoli E2 scala A 1° piano.
5.Intelligenza Artificiale: IA Generativa
![]() Gino Visciano |
Skill Factory - 01/12/2024 20:42:49 | in Home
Gino Visciano |
Skill Factory - 01/12/2024 20:42:49 | in Home
L'Intelligenza Artificiale generativa rappresenta una rivoluzione tecnologica che permette di aumentare le capacità intellettuali degli uomini; un grande passo avanti per migliorare la qualità delle attività che svolgiamo in ogni settore, perché ci permette di ridurre i tempi e i costi per gestirle.
 Oggi, gli LLM, oltre a comprendere il linguaggio naturale, possono anche creare contenuti di qualunque tipo, raggiungendo livelli di qualità molto realistici.
Oggi, gli LLM, oltre a comprendere il linguaggio naturale, possono anche creare contenuti di qualunque tipo, raggiungendo livelli di qualità molto realistici.
Questi modelli matematici sono capaci di gestire conversazioni complesse, possono supportaci durante le attività di brainstorming, ci aiutano a prendere decisioni, riescono a sintetizzare documenti, producono relazioni, fogli di calcolo e mail, scrivono codice con qualunque linguaggio di programmazione, generano contenuti artistici e di fantasia, possono interpretare il contenuto delle immagini e descriverlo in linguaggio naturale o da una descrizione sono capaci di generare un'immagine. Ad esempio, tutte le immagini di questo articolo sono state generate - attraverso una mia descrizione - dall'assistente virtuale COPILOT, che usa il modello DALL-E di OpenAI, specializzato nella generazione d'immagini.
I modelli linguistici di grandi dimensioni (LLM) hanno sviluppato queste capacità apprendendo enormi quantità dati. Praticamente riescono ad acquisire qualunque tipo d'informazioni digitale che trovano in Internet oppure che gli viene somministrata attraverso le attività di "Fine Tuning".
Più si addestrano sui dati e più diventano bravi, al punto che oggi alcuni modelli sono anche capci di superare il "Test di Turing".
Quello che è davvero sorprendente è che questi strumenti d'intelligenza artificiale, possono comprendere il sentiment espresso in un testo e capire se è positivo, negativo o neutro.
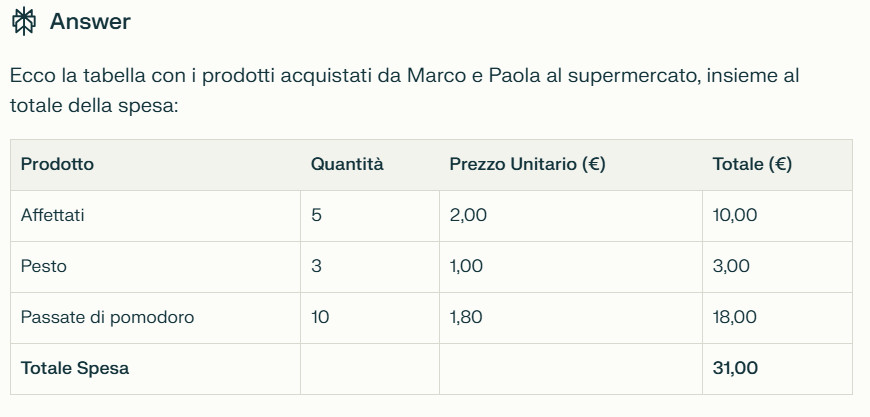
Ad esempio, guardate cosa riesce a fare l'assistente virtuale Perplexity con il testo seguente:
"Ieri Marco e Paola sono andati al supermercato e hanno comprato molti prodotti, alcuni a prezzi molto convenienti, altri un po' meno convenienti. Hanno acquistato 5 confezioni di affettati a 2 euro ciascuna, il presso è risultato conveniente, poi hanno acquistato 3 confezioni di pesto a 1 euro ciascuna, sempre al solito prezzo, quelle che sono risultate un po' care sono state le passate di pomodoro, ne prese 10 a 1,80 ciascuna.
Le cassiere sono state molto cortesi, un po' meno l'addetta alla salumeria, perché non gli ha dedicato la giusta attenzione. Il giudizio di Marco e Paola sul supermercato è buono."
Prompt 1


Prompt 2

Prompt 3

Prompt 4


Prompt 5

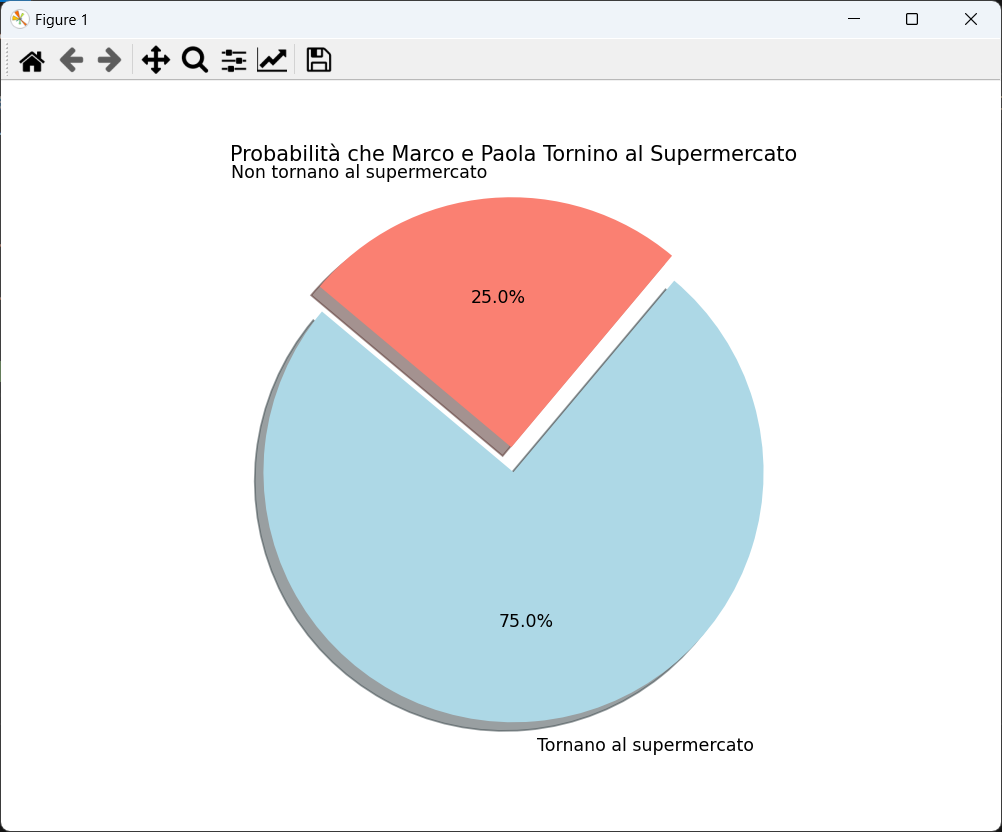
Dopo la richiesta, Perplexity ha generato il programma Python seguente:
import matplotlib.pyplot as plt
# Dati
labels = ['Tornano al supermercato', 'Non tornano al supermercato']
sizes = [75, 25] # Percentuali
colors = ['lightblue', 'salmon']
explode = (0.1, 0) # Esplodi il primo segmento
# Creazione del grafico a torta
plt.figure(figsize=(8, 6))
plt.pie(sizes, explode=explode, labels=labels, colors=colors,
autopct='%1.1f%%', shadow=True, startangle=140)
# Titolo del grafico
plt.title('Probabilità che Marco e Paola Tornino al Supermercato')
plt.axis('equal') # Assicura che il grafico sia un cerchio
# Mostrare il grafico
plt.show()
Questo è il grafico che ho ottenuto dopo l'esecuzione del codice Python:
ATTENTI AI BIAS

I dati utilizzati per addestrare gli LLM possono contenere pregiudizi questo potrebbe creare il problema dei bias.
A causa di questo problema, gli LLM potrebbero prendere decisioni discriminatorie o dare risposte che contengono pregiudizi, contribuendo a rafforzare stereotipi esistenti e creare disuguaglianze.
Anche gli algoritmi stessi possono introdurre bias, ad esempio se favoriscono determinate categorie di dati oppure le persone che progettano e utilizzano gli LLM possono introdurre i propri pregiudizi nelle fasi di sviluppo e utilizzo.
Il problema dei bias, può creare problemi etici e morali e rendere rischioso l'uso degli LLM.
Per mitigare il problema dei bias si devono utilizzare dati di addestramento diversificati e rappresentativi. Bisogna sviluppare algoritmi che siano meno suscettibili al problema e si devono valutare costantemente i modelli per individuare e mitigare i bias. Inoltre, bisogna rendere trasparenti i processi di sviluppo e di utilizzo degli LLM.
Quando usate gli LLM dovete essere consapevoli dell'esistenza dei bias e delle loro potenziali conseguenze. Chi usa un LLM deve sempre pensare in modo critico e a valutare le informazioni generate.
Conoscere il problema dei bias, significa diventare cittadini informati e consapevoli dei vantaggi e dei rischi dell'intelligenza artificiale.
LE ALLUCINAZIONI

Quando si parla di "allucinazioni" in riferimento agli LLM, non stiamo parlando di visioni o sensazioni simili a quelle umane. In questo contesto, un'allucinazione si verifica quando un LLM genera un testo che è:
Falso: Non corrisponde a fatti reali o a informazioni esistenti.
Incoerente: Non ha senso logico o contraddice informazioni precedentemente fornite.
Fuorviante: Può portare l'utente a credere in qualcosa di falso.
Le allucinazioni sono un fenomeno comune negli LLM e rappresentano una sfida importante per il campo dell'intelligenza artificiale. Tuttavia, grazie agli sforzi dei ricercatori, stiamo sviluppando sempre nuovi strumenti e tecniche per mitigare questo problema e rendere gli LLM più affidabili e utili.
Ci sono diverse ragioni per cui un LLM può generare allucinazioni:
Mancanza di conoscenza: L'LLM potrebbe non avere accesso a informazioni sufficienti per rispondere a una domanda in modo accurato.
Sovra-ottimizzazione: L'addestramento su grandi quantità di dati può portare l'LLM a "memorizzare" pattern e correlazioni che non sono necessariamente significative, generando risposte che sembrano plausibili ma sono in realtà errate.
Ambiguità: Il linguaggio naturale è intrinsecamente ambiguo e un LLM potrebbe interpretare una domanda in modo diverso da quello inteso dall'utente.
Limitazioni del modello: L'architettura stessa dell'LLM può introdurre dei bias che lo portano a generare risposte non accurate.
Addestramento su dati di alta qualità: Utilizzare dati accurati e diversificati per addestrare l'LLM.
Valutazione continua: Monitorare costantemente l'output dell'LLM e correggere eventuali errori.
Miglioramento dell'architettura: Sviluppare modelli più robusti e meno inclini alle allucinazioni.
Trasparenza: Rendere chiaro all'utente che l'LLM può generare risposte false e incoraggiarlo a verificare le informazioni.
I principali modelli utilizzati dai chatbot e dagli assistenti virtuali, sono quelli di tipo GPT, DALL-E e BERT oppure hanno le caratteristiche simili come ad esempio LLaMA.
Questi modelli d'intelligenza artificiale sono molto potenti e possono avere applicazioni diverse. La scelta del modello dipende dalle specifiche esigenze del tuo progetto.
MODELLI GPT

I modelli GPT (Generative Pre-trained Transformer) sono una delle tecnologie più avanzate nel campo dell'intelligenza artificiale generativa. Sono in grado di generare testi sorprendentemente coerenti e creativi, aprendo nuove frontiere in molti settori. Si basano sull'architettura Transformer, che è particolarmente efficace nel gestire sequenze di dati, come il linguaggio naturale.
Vengono addestrati su enormi quantità di testo, apprendendo le relazioni tra le parole e le strutture del linguaggio. Una volta addestrati, possono generare nuovi testi, traducendo, riassumendo, rispondendo a domande e molto altro.
Ad esempio, possono scrivere articoli di giornale, poesie, canzoni, script e codice sorgente e riescono a tradurre testi da una lingua all'altra con un alto grado di accuratezza. Sono capaci di riassumere lunghi documenti in pochi paragrafi, mantenendo le informazioni più importanti. Completano frasi o paragrafi iniziati dall'utente, generando testi coerenti e pertinenti.
I modelli GPT più conosciuti sono: GPT-4, sviluppato da OpenAI e Jurassic-1 Jumbo: sviluppato da AI21 Labs.
MODELLO DALL-E
OpenAi ha sviluppato anche DALL-E un modello di intelligenza artificiale che ha rivoluzionato il modo in cui pensiamo alla generazione di immagini.
DALL-E è un modello di deep learning che è stato addestrato su un enorme dataset di immagini abbinate a descrizioni testuali. Grazie a questo addestramento, è in grado di generare immagini originali e creative a partire da semplici descrizioni testuali. Puoi praticamente descrivere qualsiasi cosa tu possa immaginare, e DALL-E cercherà di tradurla visivamente.
Questo potente modello d'intelligenza artificiale può creare immagini estremamente realistiche, come fotografie di persone, animali, oggetti e scene ed è capace di generare anche immagini in stili artistici specifici, come impressionismo, cubismo, o anche stili inventati.
DALL-E è in grado di combinare concetti apparentemente non correlati, creando immagini uniche e sorprendenti.
Ad esempio, puoi chiedergli di creare un'immagine di "un gatto astronauta che guida una macchina volante":

DI seguito alcuni esempi di attività che si possono svolgere con DALL-E:
- Creare illustrazioni per libri e articoli;
- Progettare loghi e marchi;
- Generare concept art per film e videogiochi;
- Creare arte digitale unica;
- Assistere i designer nella creazione di nuovi prodotti.
MODELLI BERT

I modelli BERT (Bidirectional Encoder Representations from Transformers) sono un'altra pietra miliare nel campo dell'elaborazione del linguaggio naturale e dell'intelligenza artificiale generativa, sebbene si concentrino maggiormente sulla comprensione del linguaggio piuttosto che sulla generazione.
Come i GPT, utilizzano l'architettura Transformer, ma con un focus diverso; la caratteristica distintiva di BERT è la sua capacità di processare il testo in modo bidirezionale, considerando sia il contesto precedente che successivo di una parola. Questo gli permette di comprendere meglio il significato delle parole all'interno di una frase.
Anche BERT viene pre-addestrato su enormi quantità di testo, ma con un obiettivo diverso: comprendere il significato delle parole nel loro contesto.
Mentre i GPT sono eccellenti nella generazione di testo, le capacità generative di BERT sono più limitate e si concentrano principalmente sul significato di un testo, l'analisi del sentiment o classificazione di documenti.
Nel prossimo articolo vi parlerò dei modelli d'Intelligenza Artificiale locali e di come si possono addestrare.
1.Intelligenza Artificiale: se la conosci non la temi
2.Intelligenza Artificiale: i modelli linguistici di grandi dimensioni
3.Intelligenza Artificiale: le reti neurali artificiali
4.Intelligenza Artificiale: tipi di reti neurali artificiali
6.Intelligenza Artificiale: modelli pre-addestrati di IA locali
7.Intelligenza Artificiale: come creare una chatbot per conversare con Llama3
 FILTRI
FILTRI

 Eventi Formativi
Eventi Formativi
-

ANALISTA PROGRAMMATORE JAVA/SPRING
Napoli 02/07/2025
-

A marzo sono aperte le iscrizioni per il corso: "Microsoft 365 Expert"
08/04/2024
-

A marzo sono aperte le iscrizioni per il corso: "Agile Software Tester"
08/04/2024
-

A marzo sono aperte le iscrizioni per il corso: "Agile Full Stack Developer"
08/04/2024
-

A marzo sono aperte le iscrizioni per il corso: "SAP ABAP Developer"
08/04/2024
-

A marzo sono aperte le iscrizioni per il corso: "SAP Consultant"
08/04/2024
-

A marzo sono aperte le iscrizioni per il corso: "Big Data Analyst Developer"
08/04/2024
 Offerte di Lavoro
Offerte di Lavoro
 Post più recenti
Post più recenti
-

La qualità della formazione inizia dal confronto
12/04/2025
-
7.Intelligenza Artificiale: Come creare una chatbot per conversare con LLAMA3
15/03/2025
-
La filiera della Formazione Professionale in Europa e in Italia
16/02/2025
-
6.Intelligenza Artificiale: Modelli pre-addestrati di IA locali (Prima parte)
09/02/2025
-
Il "Tecnico Software"
16/01/2025
-
2025: "Sviluppo Software", "Amministrazione aziendale" e "Turismo Digitale", sono questi gli ambiti di qualifica professionale PAR GOL scelti dalla Skill Factory, per creare nuovi posti di lavoro
07/01/2025
-
5.Intelligenza Artificiale: IA Generativa
01/12/2024
-
4.Intelligenza Artificiale: tipi di reti neurali artificiali
25/10/2024
-
3.Intelligenza Artificiale: le reti neurali artificiali
20/10/2024
-
2.Intelligenza Artificiale: i modelli linguistici di grandi dimensioni (LLM)
11/10/2024